Key Takeaway: A well-designed data warehouse architecture separates storage from compute, enables independent scaling, and eliminates the cost of idle server capacity that drains legacy systems. The global cloud data warehouse market stands at $11.78 billion in 2025 and will reach $14.94 billion by 2026.
72% of enterprises now retire on-premise data marts in favor of unified cloud platforms. That number tells the full story of where analytics infrastructure is headed. The companies still running queries against 10-year-old on-premise servers are paying 2-3x more per query than their competitors who separated storage and compute years ago.
The cloud data warehouse market will grow by $63.91 billion between 2024 and 2029 at a 43.3% CAGR. That growth is not coming from net-new analytics buyers. It is coming from enterprises replacing broken, expensive legacy systems with data warehouse architecture patterns built for real-time AI workloads.
This guide will break down the precise models, storage layers, and design patterns that define an efficient data warehouse architecture in 2026.
Core Layers of Modern Data Warehouse Architecture
Data warehouse architecture operates through three interdependent layers: ingestion, processing/storage, and presentation. Each layer handles a specific stage of the data lifecycle, from raw extraction to BI dashboard delivery.
Modern configurations separate the storage volume from the processing power. This decoupled approach allows businesses to scale compute resources independently from data volume. A company running 50 TB of structured data does not need to provision extra processing clusters during off-peak hours. Traditional three-tier setups forced exactly that kind of wasteful over-provisioning.
The financial impact is direct. Large enterprises account for 61.35% of total analytics infrastructure spending as they execute massive cloud migrations. Most of that budget shift reflects the move from fixed-capacity servers to elastic data warehouse architecture models.
Here is how each layer operates in a production-grade environment.
1. Data Ingestion and Staging
Data ingestion is the first operational layer, responsible for extracting raw data from transactional databases, SaaS applications, IoT sensors, and flat files into a centralized staging area. By the end of 2025, the world will generate approximately 200 zettabytes of data annually, with 50% stored in cloud environments. That volume makes ingestion layer design the single biggest determinant of pipeline reliability.
Landing zones act as buffer storage between the source systems and the core data warehouse architecture. Without them, large-scale extraction jobs put direct read pressure on production databases.
A retail company pulling 200 million transaction records nightly would cripple its POS system without a properly isolated landing zone. The landing zone absorbs the extraction load, stages raw data for validation, and passes only clean records downstream.
Two extraction methods dominate in 2026 data warehouse architecture deployments. Batch ingestion collects and loads data at scheduled intervals (hourly or daily), best suited for historical reporting and compliance snapshots. Streaming ingestion uses tools like Apache Kafka or Amazon Kinesis to capture events in real time, cutting data latency from hours to seconds.
Financial services and fraud detection systems run almost exclusively on streaming pipelines because a 15-minute delay means undetected fraudulent transactions.
2. Processing and Storage Tiers
The processing tier applies transformation rules that convert raw ingested data into analysis-ready datasets. Modern platforms use columnar storage formats like Apache Parquet and ORC, which compress data at ratios of 5:1 to 10:1 and reduce storage footprints by 60-80%.
Columnar formats store values from the same column together, which makes analytical queries dramatically faster. A query scanning revenue by quarter only reads the revenue column instead of pulling every field in every row. This design is why modern data warehousing platforms process 10 to 40 billion rows per hour.
This decoupling means a company retaining 5 petabytes of historical data does not pay for high-powered compute clusters when nobody is running queries. The data warehouse architecture only activates compute resources on demand.
3. The Presentation and BI Layer
The presentation layer delivers transformed data to business users through BI dashboard tools, reports, and analytics platform interfaces. Data marts serve as dedicated subsets of the warehouse, filtered for specific business units like finance, marketing, or HR.
Restricting direct access to the underlying storage tier accomplishes two things in any data warehouse architecture. First, it prevents ad-hoc queries from competing with production ETL workloads. Second, it adds a security barrier that limits exposure of raw PII or financial records. Most compliance frameworks (SOC 2, HIPAA, GDPR) require exactly this kind of layered access control in modern data warehousing environments.
Understanding the base architecture is only half the equation. The next consideration is how multi-cloud deployment changes the economics and resilience of these layers.
The Shift Toward a Multi-Cloud Data Warehouse
A multi-cloud data warehouse distributes storage and processing across two or more cloud providers (AWS, Azure, Google Cloud) to eliminate single-vendor dependency and improve disaster recovery coverage.
Over 60% of enterprises now split workloads across multiple cloud vendors. This is not a technology preference. It is a risk management strategy. When AWS experienced its major US-East-1 outage in October 2025, companies running a single-cloud data warehouse architecture lost access to reporting for hours. Multi-cloud deployments routed traffic to Azure or GCP within minutes.
1. Achieving Cost Efficiency with FinOps
FinOps practices give data warehouse architecture teams real-time visibility into cloud spending and the ability to optimize it continuously. The core principle: shift workloads dynamically to the cheapest available region or provider based on current pricing and utilization.
A manufacturing company running nightly batch transforms can schedule those jobs in a region where spot pricing drops 40-60% during off-peak hours. Without FinOps tooling, most teams discover overspending only at the end of the billing cycle, after the money is already spent.
2. Serverless Compute Capabilities
Serverless compute segments within the cloud data warehouse market are growing at a 29.94% CAGR, outpacing nearly every other deployment model. The financial advantage is straightforward: pay-per-query pricing replaces fixed provisioned instances entirely.
During seasonal retail events like Black Friday or financial closing periods, serverless platforms auto-scale compute resources to match demand spikes without any manual intervention. Snowflake’s per-second billing model and BigQuery’s slot-based pricing both tie cost directly to actual query execution time.
“Scaling your data warehouse depends on robust source connectivity, particularly for high-volume online retail ingestion. Discover how to handle these connections in E-commerce API Integration: Ensuring High Scalability.”
When traffic drops, costs drop to near zero. A company that processes 500 queries per day during normal operations and 50,000 during quarter-end only pays for those peak hours, not for 24/7 provisioned capacity sitting idle the other 89 days of the quarter.
3. Ensuring Security Across Environments
Maintaining consistent access policies across AWS, Azure, and GCP requires unified identity management. Each provider uses different IAM frameworks, different permission models, and different audit log formats. Banking, financial services, and insurance (BFSI) firms, which account for 27.45% of the cloud data warehouse market, face the strictest compliance requirements across these environments.
Centralized governance platforms consolidate these into a single control plane. This prevents the most common multi-cloud security failure: an engineer grants broad read access in one environment without realizing it exposes production data across all connected data warehouse architecture environments.
Multi-cloud security solves the infrastructure risk. But architecture design patterns determine how efficiently data flows within these environments.
Key Design Patterns in Modern Data Warehousing
Modern data warehousing design patterns have shifted from monolithic, single-server setups to distributed, AI-integrated architectures that process high-volume data with automated schema management and real-time ML inference.
The older approach treated the warehouse as a passive storage box. Data went in through scheduled ETL jobs, sat in fixed schemas, and waited for analysts to query it. The 2026 data warehouse architecture pattern integrates machine learning directly into the data pipeline. The warehouse itself identifies anomalies, recommends schema changes, and auto-tunes query execution plans.
The data warehousing market reached $34.49 billion in 2024 and is projected to hit $65.46 billion by 2032, growing at an 8.34% CAGR. That growth tracks directly with the adoption of these newer design patterns.
Quick Glance: Key Design Patterns Compared
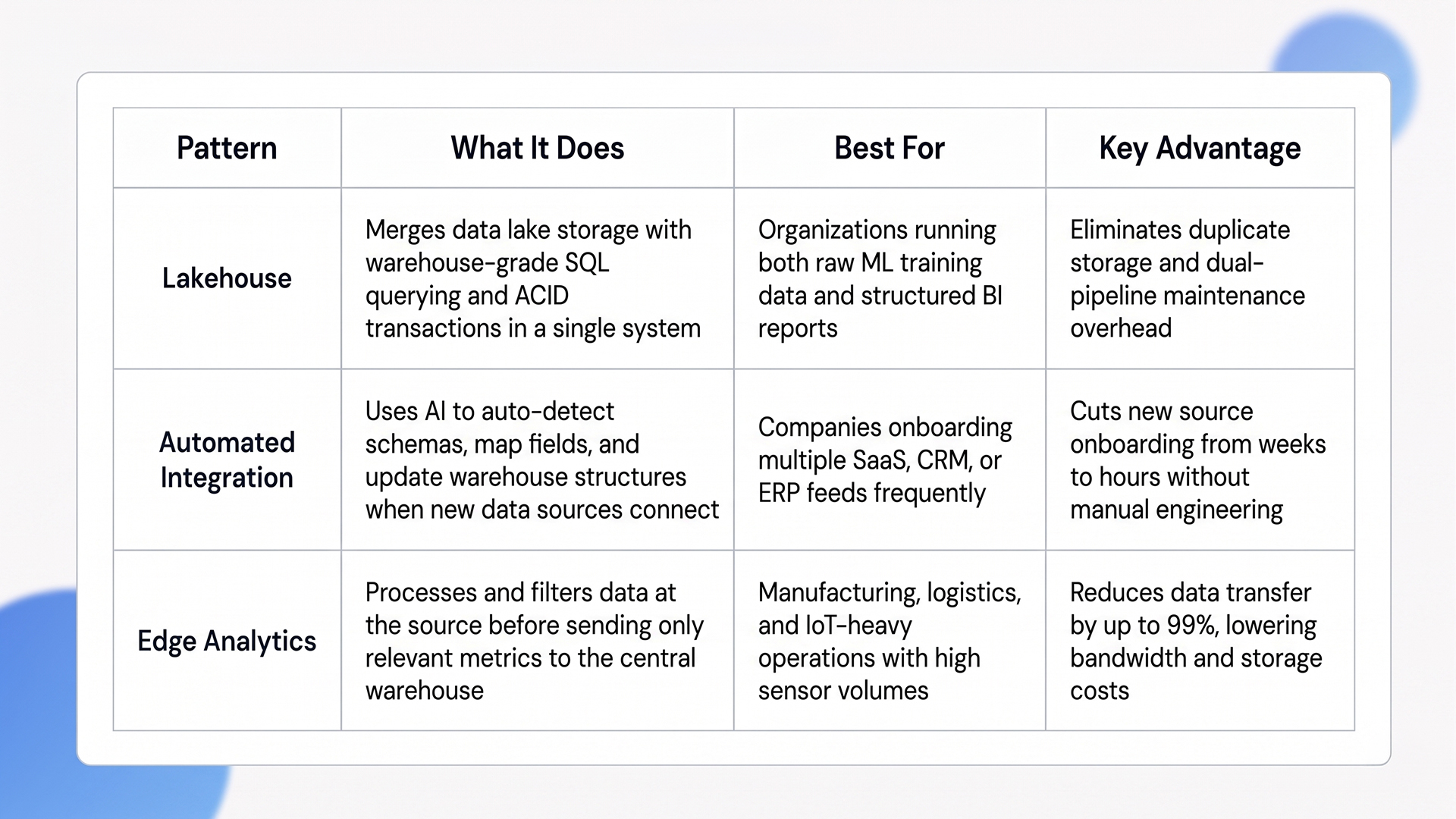
1. The Rise of Lakehouse Models
The data lakehouse concept merges the low-cost, schema-on-read storage of a data lake with the structured querying and ACID transaction support of a traditional warehouse. This hybrid eliminates the need to maintain two separate systems.
Before the lakehouse model, companies stored raw unstructured data in a lake and copied processed subsets into a warehouse for SQL analytics. That duplication wasted storage, created data consistency issues, and added engineering overhead. A modern data warehousing lakehouse stores everything once and applies governance, schema enforcement, and SQL-compatible query layers on top of the same storage layer.
“Modern architecture prioritizes separating storage from compute to optimize real-time AI workloads. We explore why platforms like Snowflake lead this shift in The Convergence of AI and Cloud Data.”
2. Automated Data Integration
AI-driven data integration tools now automate schema mapping, a process that previously required manual engineering work every time a new data source was onboarded. Intelligent ingestion tools detect new data structures, validate field types, and update warehouse schemas without human intervention.
Gartner predicts that through 2026, organizations will abandon 60% of AI projects not supported by AI-ready data. That prediction underscores why automated schema detection and data quality checks inside the data warehouse architecture pipeline are now operational requirements, not optional upgrades.
The practical impact: a company adding a new CRM or ERP data feed no longer needs two weeks of engineering time to map fields and test pipelines. The automation layer handles it within hours, which is a competitive advantage when speed of data warehouse architecture deployment determines time-to-insight.
3. Implementing Edge Analytics
Processing data at the source (edge nodes) instead of sending everything to a centralized warehouse reduces latency and network bandwidth costs. Manufacturing and logistics companies use edge analytics to filter out irrelevant sensor data before transmitting only meaningful metrics to the core data warehouse architecture.
A factory floor generating 500 GB of sensor telemetry daily might only need 5 GB of aggregated production metrics in the central warehouse. Edge nodes handle that 99% reduction locally, saving significant data transfer and storage costs.
Design patterns define how data flows efficiently. The next priority is ensuring the architecture handles real-world operational stress without breaking.
Overcoming Bottlenecks in Data Warehouse Architecture
Data warehouse architecture bottlenecks occur when data volumes spike unexpectedly, concurrent queries compete for compute resources, or schema changes corrupt ingestion pipelines. Addressing these requires workload isolation, schema governance, and incremental migration strategies.
Most teams design their architecture for average load, not peak load. That works until a quarterly financial close, a marketing campaign, or an ML training job sends query volumes to 10x normal levels. The platforms that survive these spikes are the ones that isolate workloads at the architecture level, not the ones that add more servers.
Quick Step: Bottleneck Diagnosis and Fix
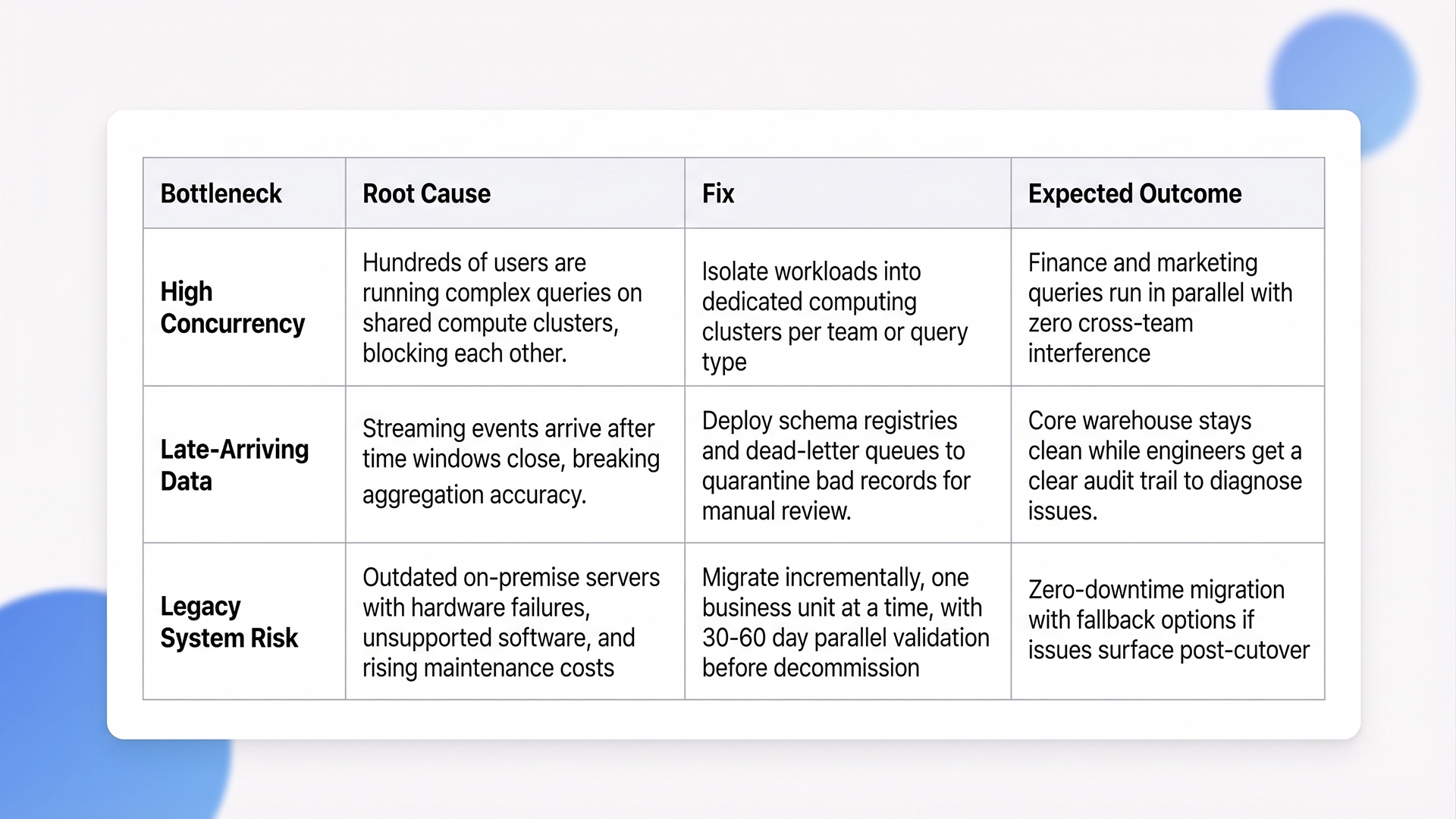
1. Managing High Concurrency Limits
Performance degrades sharply when hundreds of users run complex analytical queries at the same time against a single data warehouse architecture. Modern cloud data warehouse platforms handle this through workload isolation, assigning separate computing clusters to different teams or query types.
Query concurrency exceeds 5,000 sessions in large enterprise environments. Without isolation, a financial analyst running a full-year revenue aggregation can block a marketing team’s real-time campaign dashboard for minutes. Workload isolation ensures each group operates on a dedicated compute without interference.
2. Handling Delayed Events and Schema Changes
Late-arriving data is a constant problem in streaming data warehouse architecture pipelines. A payment confirmation arriving three hours after the transaction timestamp can break time-windowed aggregations if the pipeline does not account for it.
Schema registries enforce strict structural rules on incoming data. When a source system changes a field from integer to string, the registry rejects the record and routes it to a dead-letter queue for manual review instead of allowing it to corrupt downstream tables.
This quarantine approach keeps the core data warehouse architecture clean while giving engineers a clear audit trail to diagnose issues.
3. Upgrading Legacy Systems
Maintaining outdated on-premise servers creates compounding risk: hardware failures, unsupported software versions, and escalating maintenance contracts. The cost of a single unplanned outage on a legacy warehouse often exceeds the entire first-year budget of a cloud migration.
“AI-driven ingestion tools are transforming how we handle data drift and integration. For a wider look at simplifying AI implementation, read AI Automation for Business: Low-Code Strategies for High-Impact Growth.”
Incremental migration is the proven approach. Move one business unit at a time, validate data parity between old and new systems, and decommission legacy components only after the new data warehouse architecture runs stable in production for 30-60 days. Full rip-and-replace migrations fail at significantly higher rates because they leave zero fallback options.
How Ariel Software Solutions Builds Production-Grade Data Warehouse Architecture

Most data warehouse architecture failures trace back to the same engineering problems: coupled storage and compute layers bleeding budget on idle clusters, ingestion pipelines that break silently when upstream schemas change, and BI teams waiting hours for queries that should return in seconds. These are structural issues that require architecture-level fixes, not bigger servers.
Ariel Software Solutions has solved these exact problems across 1,100+ projects for 800+ clients over 15+ years, backed by a 95% satisfaction rate on Clutch, Upwork, and Freelancer.
- Zero-Downtime Cloud Migration: We move legacy on-premise warehouses to cloud-native, AI-ready architectures one business unit at a time, keeping production systems live throughout the transition.
- Pipeline-Level AI Assessment: Before writing a line of code, Our engineers identify where automation can fix schema drift, optimize query execution plans, and reduce ingestion failures.
- Post-Launch Performance Tuning: Ongoing monitoring, security patches, and warehouse optimization prevent compute costs from creeping back up after deployment.
For teams running a warehouse that is slow, expensive, or breaking under load, book a quick architecture review with Ariel’s data engineering team.
Conclusion
Updating a data storage strategy is a baseline requirement for operational efficiency in 2026. A properly configured data warehouse architecture reduces compute costs, eliminates reporting delays, and delivers accurate business intelligence across every department.
Companies still coupling compute and storage in legacy setups will continue overpaying for basic analytics while competitors run real-time AI workloads at a fraction of the cost. The architecture decisions made today determine an organization’s analytics capability for the next five years.
Explore Ariel’s custom data warehouse architecture solutions and book a quick walkthrough to see how it fits any existing data stack.
Frequently Asked Questions
1. What are the 3 main types of data warehouse architectures?
The three primary types are single-tier, two-tier, and three-tier structures. A three-tier model is the modern standard. It divides operations into a bottom database server tier, a middle analytical processing tier, and a top front-end client tier for BI dashboards and direct user reporting.
2. How does a data lake differ from a data warehouse?
A data lake stores massive volumes of raw, unstructured data in its native format using a schema-on-read approach. No predefined structure is applied until query time. A warehouse stores highly structured, filtered, and processed data with schema-on-write enforcement, optimized specifically for fast SQL querying and immediate business intelligence reporting.
3. Why is separating storage and compute important?
Decoupling these two layers allows organizations to scale processing power independently from data volume. This prevents companies from paying for expensive compute clusters when running simple queries. It ensures high performance during peak traffic while keeping baseline storage costs low.
4. What is a data lakehouse model?
A lakehouse is a hybrid design that combines the cheap, flexible storage capacity of a data lake with the structured data management and transaction features of a warehouse. This unified system eliminates data silos and reduces the complexity of maintaining two separate data pipelines.
5. How do serverless data warehouses reduce costs?
Serverless models use a pay-per-query pricing structure instead of charging for fixed server capacity. Companies only pay for the exact computing resources used during active data processing. When the system is idle, costs drop to near zero, eliminating the financial waste of constantly running provisioned instances.


