
Key Takeaway: Most enterprises are spending heavily on generative AI but missing returns. Global GenAI spending will hit $644 billion in 2025, yet nearly 45% of AI use cases are missing their ROI targets. The gap between pilot and production is where most generative AI challenges play out.
65% of organizations adopted AI in 2024, yet less than 5% have successfully scaled beyond a pilot. That gap is where every generative AI challenge actually plays out, not in the model, but in the architecture, governance, and integration decisions surrounding it.
Global GenAI spending hit $644 billion in 2025, with 45% of use cases missing their ROI targets. The companies falling short aren’t choosing the wrong models. They’re making the wrong infrastructure bets before a single prompt is written.
This guide breaks down every core generative AI challenge blocking enterprise teams in 2026, and the specific decisions that separate deployments that scale from those that don’t.
Core Technical Generative AI Challenges in 2026
The most expensive generative AI challenges at the technical level aren’t model quality problems. They’re infrastructure, cost, and architecture decisions that most pilot environments never stress-test, and don’t reveal their cost until production load hits.
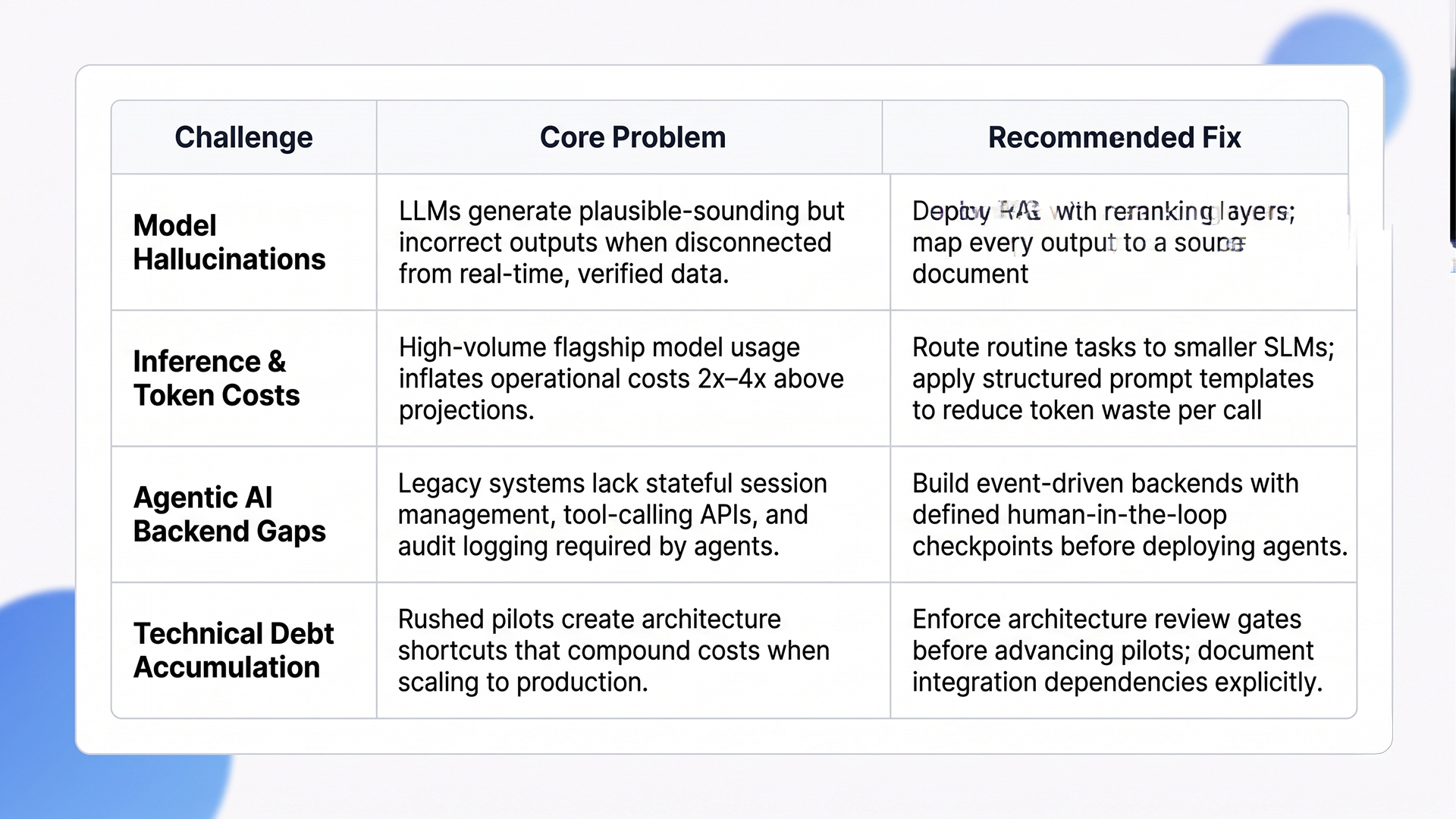
Quick Glance: Core Technical Challenges and Fixes
1. Solving the Hallucination Problem with RAG
Model hallucinations are predictable, not random: raw LLMs without grounding will confidently produce incorrect outputs when trained data diverges from what’s true in your operating environment. The practical fix is Retrieval-Augmented Generation (RAG), which pulls your proprietary data into the model’s context at inference time instead of relying on static training weights.
RAG reduces hallucination rates by up to 60% in enterprise deployments by grounding outputs in verified, current data sources. In sectors like healthcare, legal, and finance, where a single fabricated figure triggers liability, RAG is a non-negotiable architecture requirement, not a performance enhancement.
The teams with the highest accuracy scores in 2026 aren’t just running RAG. They’re pairing it with reranking layers and citation tracking, so every AI output traces back to a specific source document that can be audited.
2. Managing the Infrastructure Tax and Token Costs
Token costs have shifted from a dev-budget footnote to a direct P&L concern. As AI workflows scale in volume and complexity, inference costs compound fast. Organizations running high-volume generative AI workflows on flagship models like GPT-4o are reporting operational costs 2x to 4x above initial projections without deliberate cost architecture in place.
The primary control strategy in 2026 is model routing: smaller specialized language models (SLMs) handle routine classification, summarization, and extraction, while large models are reserved for complex, multi-step reasoning. This hybrid architecture cuts inference costs by 40-70% without degrading output quality on the tasks that matter most.
“Understanding where implementation breaks down is only half the picture. The other half is knowing where the technology is heading, covered in full in Generative AI Trends.”
Prompt engineering discipline compounds these savings. Structured prompts with defined output formats reduce token consumption per call and make responses faster to process downstream, which matters at scale.
3. The Shift to Agentic AI Workflows
The enterprise AI conversation has moved well past chatbots. The GenAI scalability barrier here is backend architecture. Agentic systems require stateful session management, tool-calling infrastructure, human-in-the-loop checkpoints, and audit logging. Most legacy enterprise systems support none of these natively. Teams building agentic workflows on unprepared infrastructure are generating technical debt faster than they’re shipping value.
The organizations advancing fastest in agentic AI share one trait: they invested in clean API layers and event-driven backends before they deployed agents, not after the architecture problems became visible at scale.
Beyond the technical stack, the harder AI implementation hurdles sit in legal, compliance, and ethics, and they’re getting harder to defer.
Overcoming Ethical AI Implementation Hurdles
Security and ethics aren’t compliance checkboxes. They’re architecture decisions that determine whether your AI deployment is legally viable and commercially sustainable at scale. Skipping governance frameworks at the start creates compounding AI implementation hurdles that get more costly to fix with every deployment layer added on top.
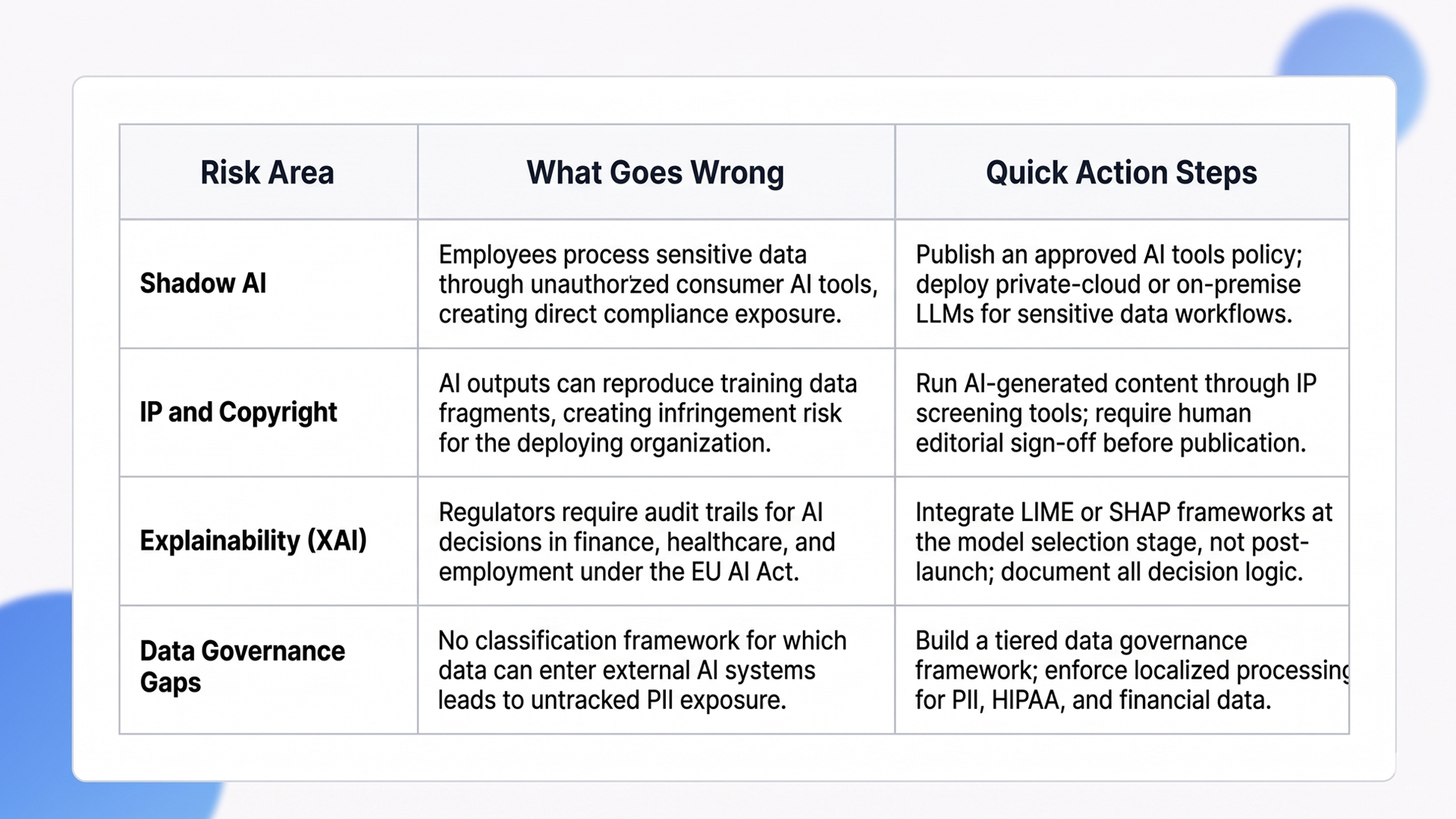
Quick Glance: Ethical AI Risks and Action Steps
1. Data Privacy in the Era of Shadow AI
“Shadow AI” is the enterprise security problem most IT teams discovered after it was already widespread. For organizations handling PII, financial data, or HIPAA-regulated records, employees routing work through personal ChatGPT accounts creates direct, auditable compliance violations.
The practical response requires three concurrent layers: a data governance framework that classifies which data types can enter external AI systems, localized processing through on-premise or private-cloud LLM deployments for sensitive workflows, and mandatory usage policies backed by audit trails.
Organizations that treat shadow AI as a technology access problem consistently fail to contain it. Blocking tools without providing sanctioned alternatives drives the behavior further underground. The fix is governance plus infrastructure, in that order.
“Shadow AI and compliance gaps don’t stop at the application layer. How AI integrates with DevOps security practices determines the actual exposure surface, covered in Generative AI in DevOps Security.”
2. Intellectual Property and Legal Liability
Who owns AI-generated content? In 2024, the US Copyright Office formally confirmed it will not register copyright for purely AI-generated works without sufficient human authorship. For companies using GenAI to produce marketing copy, code, or product documentation at volume, this creates a concrete IP gap in their content portfolio.
The exposure runs in both directions: AI outputs can reproduce fragments of training data, creating infringement risk for the deploying organization, even if the model vendor owns the generation. Legal teams in 2026 are requiring copyright similarity screening on all AI-generated content before it goes live, not as a post-publication review.
The organizations with the lowest IP exposure are treating AI as a drafting accelerator, with human editorial review as a mandatory final step, not an optional quality check.
3. Achieving Explainability in Black-Box Models
Regulators in the EU, US, and UK are requiring audit trails for AI decisions in high-stakes sectors. The EU AI Act, in active enforcement since 2024-2025, mandates that high-risk AI systems document the reasoning behind every decision in finance, healthcare, and employment contexts. Non-compliance penalties under the Act reach 3-7% of global annual revenue.
Explainable AI (XAI) frameworks like LIME and SHAP let teams trace why a model produced a specific output, down to feature weights. The implementation overhead is real: it adds inference latency and requires ML interpretability skills that most enterprise IT teams are still building. But the cost of retrofitting explainability post-launch is consistently higher than engineering it upfront.
The most practical approach: make explainability a procurement criterion. Models with native audit logging and structured reasoning outputs are measurably cheaper to bring into compliance than black-box endpoints evaluated only on accuracy benchmarks.
Governance covers the compliance floor. The harder problem, for most teams, is why generative AI challenges that clear compliance still stall before scale. That’s the GenAI scalability barrier territory.
Breaking Pilot Purgatory: Solving GenAI Scalability Barriers
“Pilot purgatory” is quantifiably expensive. The issue isn’t always technical capability; it’s architectural decisions, strategic clarity, and organizational alignment failing simultaneously. Solving GenAI scalability barriers means addressing all three.
1. Integrating AI with Legacy Enterprise Systems
The most common GenAI scalability barrier in 2026 is the architecture divide: ERPs, CRMs, and data warehouses built over decades weren’t designed to expose clean APIs or stream real-time data to external inference engines. Teams are forced to choose between full system migration or middleware workarounds that accumulate technical debt with every new integration.
The 2026 playbook centers on event-driven integration layers (Kafka, AWS EventBridge, Azure Event Grid) that route data from legacy systems to AI pipelines without modifying core infrastructure. This approach cuts integration timelines by 30-50% compared to direct system rewrites and keeps production systems stable throughout the process.
“Most implementation failures traced here originate in how development is scoped, not how models perform. Generative AI Development Services covers the engineering process that prevents those gaps from forming.”
The highest-value integration targets in 2026 are systems generating the most unstructured data: customer support logs, contract repositories, and maintenance records, because these are exactly where structured ML pipelines previously couldn’t extract usable signals.
2. From Generative Features to AI-First Processes
Placing a chat widget on an existing product isn’t scaling AI; it’s a surface decoration that adds cost without changing process economics. Real scaling means redesigning high-volume processes around AI logic: automating routine decision layers, replacing manual document review with model-assisted triage, and moving analyst work from data collection to data validation.
The structural difference is direct: process redesign removes the underlying inefficiency, while feature addition mildly accelerates it.
The teams making this shift fastest start by mapping every manual decision in a high-volume process, categorizing them as routine (AI-owned) or exception-based (human-in-the-loop), and automating the routine tier first to generate fast ROI evidence for the next funding cycle.
3. Measuring Real ROI Beyond the Hype
Vanity metrics don’t survive CFO review. “Employee satisfaction with AI” and “prompts run per week” aren’t business outcomes. The shift in 2026 is to EBIT-level impact: hours saved converted to realized cost reduction, error rate deltas before and after deployment, customer resolution times, and direct revenue per AI-assisted transaction.
Teams that skip baseline measurement have no credible answer when finance questions the return. The measurement framework needs to exist before the first line of production code is written, not six months after launch.
The most defensible AI ROI cases in 2026 share one structural trait: the AI output is mapped directly to a metric that already exists in the company’s P&L, not a proxy invented to look productive.
Getting infrastructure and strategy aligned still isn’t enough if the people running the system aren’t equipped. That’s where the AI implementation hurdle becomes a people problem.
Cultural Readiness and Skill Gaps: The Human Factor
Every major generative AI challenges survey from 2024-2025 consistently places talent and culture in the top three blockers, above both cost and technology. The Stanford HAI 2025 AI Index found that AI skill gaps are cited by 55% of enterprises as a primary barrier to deployment scale. You can have the right infrastructure and still stall here.
1. Closing the AI Literacy Gap in the Workforce
There’s a growing divide in most enterprise workforces between employees using AI as a genuine productivity multiplier and those who treat it as unreliable or irrelevant. Training programs that stop at tool access, “here’s how to open Copilot,” produce no measurable change in output quality. Effective AI literacy programs build mental models: when AI is appropriate, how to evaluate AI-generated outputs critically, and how to identify where the model is likely to be wrong.
Workers with structured AI literacy training are 34% more productive on complex tasks than untrained peers. The ROI on structured upskilling is measurably faster than most new model deployments, and the risk profile is lower.
Prompt engineering training yields compounding returns. Teams that write precise, structured prompts get consistently higher-quality outputs, which directly cuts the human review overhead that makes many AI deployments operationally expensive at volume.
2. Addressing AI Fatigue and Job Displacement Concerns
Internal resistance to AI adoption isn’t irrational. Employees watching colleagues’ roles get restructured have concrete reasons to distrust “AI will augment your job, not replace it” messaging, especially when it comes from leadership that recently reduced headcount. Vague reassurance without specifics accelerates distrust rather than reducing it.
Organizations that explicitly redefine job roles around AI integration, documenting exactly which tasks shift to AI, which stay human, and what new responsibilities the position gains, see AI adoption rates 40% higher than those running generic change management campaigns.
The organizations with the lowest internal resistance share one practice: they asked frontline employees which tasks felt most tedious and repetitive, then built the first AI deployment phase around automating exactly those tasks. Ownership of the problem translates directly into adoption of the solution.
3. The Rise of the Chief AI Officer (CAIO)
By 2026, the CAIO role will have become standard in enterprise org structures. The function operates as the bridge between ML engineering teams building the systems and business stakeholders making decisions from them. CAIOs own AI governance policy, cross-department adoption strategy, and the ROI measurement framework that finance actually accepts.
Organizations without this role tend to run fragmented AI strategies, with each business unit operating independent pilots that never share infrastructure, data, or learnings.
The CAIO is most effective when the role carries both engineering credibility and revenue accountability, a combination that prevents the function from being siloed in IT or delegated entirely to strategy teams who can’t evaluate technical trade-offs.
Closing the people and structure gaps addresses the final layer of generative AI challenges. What’s left is choosing the right build partner for what comes next.
How Ariel Software Solutions Addresses Generative AI Challenges

Ariel’s engineering team has worked through every generative AI challenge covered here across 1,100+ projects: grounding hallucination-prone LLMs with production-grade RAG pipelines, connecting agent workflows to legacy ERPs without system rewrites, and building governance frameworks that satisfy EU AI Act audit requirements.
Our 15 years of cross-industry deployment experience mean the architecture decisions that stall most teams, data classification, cost routing, and explainability are solved problems at Ariel before scoping even begins. See how Ariel builds it for your stack.
Conclusion
The generative AI challenges most organizations face in 2026 aren’t gaps in model capability. They’re gaps in how AI is architected, governed, and integrated into existing systems and teams. The 45% of AI use cases missing ROI targets are missing them because of decisions made before deployment, not after.
Addressing AI implementation hurdles and GenAI scalability barriers systematically, starting with data grounding, infrastructure readiness, and governance, consistently outperforms approaches that chase model releases without solving the underlying architecture. The organizations scaling AI in 2026 are the ones that treated the foundations as seriously as the features.
If your deployments are stalling between pilot and production, let’s look at the specific blockers. Book a technical review with Ariel and get a concrete path forward.
Frequently Asked Questions
1. Why do most GenAI projects fail to scale in 2026?
Most generative AI challenges at the scaling stage trace back to three structural gaps: no scalable data architecture, poor integration with legacy systems, and ROI metrics that weren’t defined before launch. McKinsey’s 2024 data confirms that less than 5% of organizations have advanced AI beyond proof-of-concept (McKinsey, 2024).
2. How can enterprises reduce AI token costs without losing output quality?
Route routine tasks, classification, summarization, and extraction, to smaller specialized models, and reserve large-scale models for complex reasoning. This model routing architecture cuts inference costs by 40-70% with minimal quality loss. Structured prompt templates with defined output formats reduce token consumption per call and speed downstream processing.
3. What is agentic AI, and why does it require different infrastructure?
Agentic AI systems execute multi-step workflows autonomously, calling external tools and making sequential decisions within defined guardrails. Unlike chatbots, agents require stateful session management, tool-calling APIs, human-in-the-loop checkpoints, and audit logging, none of which most legacy backends support natively. Architecture preparation before deployment is non-negotiable.
4. How does RAG address the hallucination problem in enterprise deployments?
RAG retrieves verified documents from your own data store at inference time, giving the model factual grounding before it generates a response. This approach reduces hallucination rates by up to 60% in enterprise contexts because the model works from current, auditable sources rather than static training data (IBM Research, 2024). Pairing RAG with citation tracking creates a full audit trail for every AI output.
5. Is structured AI literacy training worth the cost for enterprise teams?
The ROI is faster than most AI technology investments. Workers with structured AI literacy programs are 34% more productive on complex tasks than those without training (MIT Sloan, 2024). The payback period is typically under 90 days when measured against reduced output review overhead and higher first-pass quality from better-structured prompts.


