Key Takeaway: The global real-time analytics market is expected to reach $1.09 billion in 2025, growing toward $5.26 billion by 2032 at a 25.1% CAGR. Real time data processing is no longer an optional infrastructure. Companies still running batch-only pipelines are making decisions on data that was stale hours ago.
By 2025, roughly 30% of all generated data is expected to be real-time. That projection explains why batch processing, the default for enterprise data teams over the past two decades, is losing ground fast. Real time data processing has shifted from a performance bonus to the baseline expectation for any data-driven operation.
Meanwhile, 86% of IT leaders now rank data streaming investments as a top strategic priority. Organizations still queuing data for nightly ETL runs are working with information that expired before anyone looked at it. This guide will break down the architecture, top tools, and high-impact use cases for real time data processing in 2026.
The Core Architecture of Real Time Data Processing
Real time data processing replaces scheduled batch runs with continuous micro-batch and event-stream execution, reducing data latency from hours to milliseconds. This architecture processes records the moment they arrive instead of storing them for later analysis.
Modern data pipelines built for real time data processing differ from legacy batch systems in one fundamental way: they treat data as a stream, not a stored set. Batch architectures collect records into files, schedule a processing window, and deliver results hours or days after the original event. Streaming data architecture flips this model. Every record triggers processing the instant it enters the pipeline.
This shift demands components optimized for continuous throughput: message brokers, stream processing engines, and in-memory state stores. The goal is low latency at every stage, from ingestion to output. Batch systems tolerate delay by design. Streaming systems treat delay as failure.
1. Data Ingestion vs Stream Processing
Data ingestion handles the collection and transport of raw events into the pipeline. Stream processing applies transformations, aggregations, and logic to those events in flight. These are separate layers, and treating them as one creates fragile systems.
Ingestion tools (Kafka producers, Fluentd, AWS Kinesis Data Streams) focus on reliable capture at scale. Processing engines (Apache Flink, Spark Structured Streaming) handle computation. Efficient data ingestion is the prerequisite for valid stream processing.
If ingestion drops records or delivers them out of order, no downstream logic can fix the output. The most common mistake teams make: picking a processing engine before validating that their ingestion layer can handle peak throughput without data loss.
2. Building an Event-Driven Architecture
An event-driven architecture structures applications around state changes. Instead of polling databases or running scheduled queries, services react to events the moment they are published.
This design decouples producers from consumers. A payment service publishes an event. Inventory, notifications, and analytics each consume it independently. When data volume spikes, the message broker absorbs the surge while individual services scale at their own pace. Tightly coupled architectures collapse under this kind of load because every component inherits the slowest service’s bottleneck.
With the architecture model clear, the next question is which tools power this at scale.
Top Real-Time Analytics Tools Leading in 2026
Real-time analytics tools in 2026 split into three categories: open-source engines for teams that need full control, managed cloud services for operational simplicity, and a growing set of Kafka-compatible alternatives optimized for cost and latency.
The software layer of a streaming data architecture handles message brokering, stateful computation, and output delivery. Choosing the right combination depends on data volume, team size, and infrastructure maturity.
The market has consolidated around Kafka-based ecosystems, but the way teams deploy Kafka looks very different in 2026 than it did two years ago.
Quick Tool Glance:
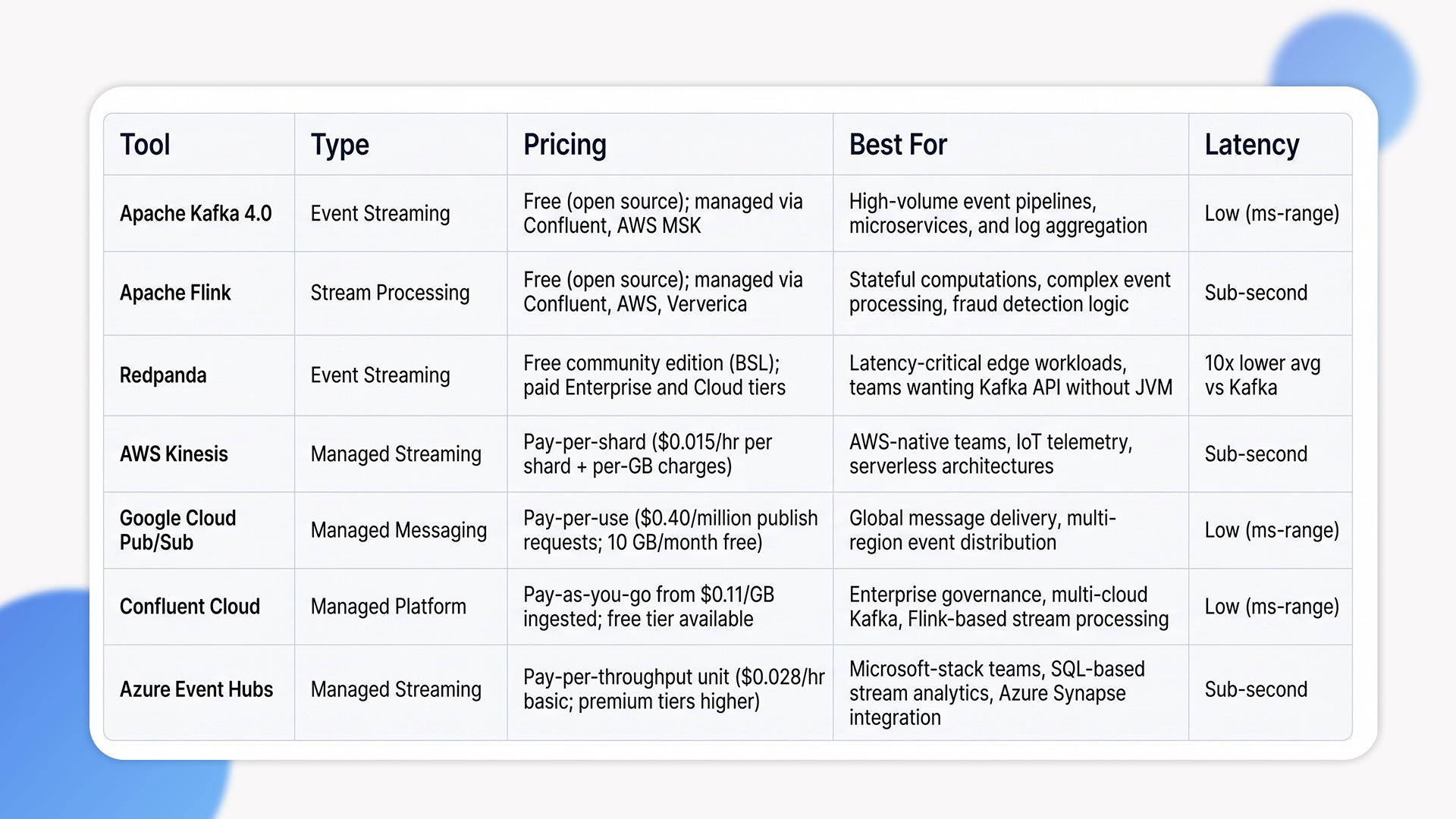
1. Apache Kafka and Flink for Heavy Workloads
Apache Kafka remains the standard for high-volume distributed messaging. Kafka 4.0, released in March 2025, fully removed ZooKeeper and replaced it with KRaft. This change raised the partition ceiling to 1.9 million partitions per cluster and made topic creation an O(1) operation. For teams that delayed upgrading because of ZooKeeper overhead, that blocker is gone.
Apache Flink pairs with Kafka for stateful stream processing, supporting exactly-once semantics and complex event-time windowing. Confluent has shifted its strategic focus to Flink as the stream processing standard, replacing ksqlDB for new deployments (Kai Waehner, Data Streaming Landscape 2026). LinkedIn alone processes over 7 trillion messages per day through Kafka. At that scale, the Kafka-Flink combination is hard to replace.
2. Redpanda and Managed Cloud-Native Solutions
Redpanda, a C++ Kafka-compatible engine, targets teams that want lower latency and simpler operations. It runs as a single binary with no JVM dependency and delivers 10x lower average latencies on identical hardware. Its adoption remains concentrated in edge and performance-critical use cases, with broader enterprise traction still limited.
AWS Kinesis and Google Cloud Pub/Sub offer managed real-time analytics tools that eliminate broker cluster maintenance. For smaller engineering teams, managed services reduce patching, scaling, and monitoring overhead significantly. The trade-off: less granular control over partitioning and processing semantics compared to self-hosted setups. For most mid-market use cases, that trade-off is worth it.
Selecting the right tools matters, but the real payoff shows up in specific business applications.
High-Impact Use Cases for Real Time Data Processing

Real time data processing delivers the highest ROI in industries where milliseconds directly affect revenue, risk exposure, or customer retention. Financial services, IoT, and manufacturing lead adoption because delayed information in these sectors creates measurable losses.
1. Instant Fraud Detection in Financial Services
Modern fraud detection systems complete risk assessments in 200 to 300 milliseconds per transaction. Mastercard’s Transaction Fraud Monitoring platform operates at 100 to 120 milliseconds in the cloud and under 10 milliseconds on-premise. American Express processes transactions against a 2-millisecond latency requirement using over 1,000 decision trees.
Combining real time data processing with graph databases adds another detection layer. Graph queries identify connected fraud rings across accounts that statistical models miss. Deloitte’s Center for Financial Services estimates banks will suffer $40 billion in losses from generative-AI-enabled fraud by 2027, up from $12.3 billion in 2023. The systems that stop these losses operate on stream processing pipelines, not batch reports reviewed the next morning.
2. Edge Computing in IoT and Manufacturing
IoT data processed at the edge computing layer prevents catastrophic machinery failures. Sensors on industrial equipment generate thousands of readings per second. Sending all of that to centralized data warehousing introduces latency that defeats the purpose of monitoring in the first place.
Local processing at the edge filters, aggregates, and acts on sensor data before forwarding summaries to the cloud. Gartner had predicted that 75% of enterprise data would be created and processed outside traditional data centers by 2025. That forecast has largely materialized. Manufacturing plants running predictive maintenance on edge nodes catch equipment degradation days before failure, which is something centralized batch analysis cannot deliver with the same response time.
These use cases prove the value, but keeping pipelines healthy at scale introduces its own set of operational problems.
Optimize Real-Time Data Pipelines for Long-Term Maintainability with Ariel Software Solutions
Most real time data processing failures are not tool failures. They are architecture failures. Teams pick a streaming engine, connect it to a few sources, and call it production-ready. Six months later, consumer lag spikes during peak hours, schema changes break downstream services, and no one owns the monitoring layer. These are the problems that stall growth after the initial deployment.
Ariel Software Solutions has solved these exact problems across 1,100+ production projects. Our engineering team audits existing streaming data architecture for partition imbalance, identifies latency bottlenecks in data pipelines, and builds schema governance into CI/CD workflows before broken contracts reach production.
For legacy systems, Ariel migrates batch infrastructure to cloud-native, AI-ready architectures without disrupting live operations.
If your pipelines are creating delays instead of real-time insights, book a 15-minute architecture review with Ariel to pinpoint where performance breaks down and how to fix it.
Overcoming Streaming Data Architecture Bottlenecks
Streaming data architecture bottlenecks surface at three predictable points: partition imbalance, consumer group lag, and schema drift. Each degrades pipeline reliability differently, and each requires a different fix.
Batch systems fail visibly: a job either runs or it does not. Streaming systems degrade silently. A 200ms increase in consumer lag during off-peak hours becomes a 3-second backlog during peak traffic. Without real-time monitoring on your real time data processing infrastructure, these issues compound until the entire pipeline stalls.
Quick Step Glance: Diagnosing and Fixing Common Bottlenecks
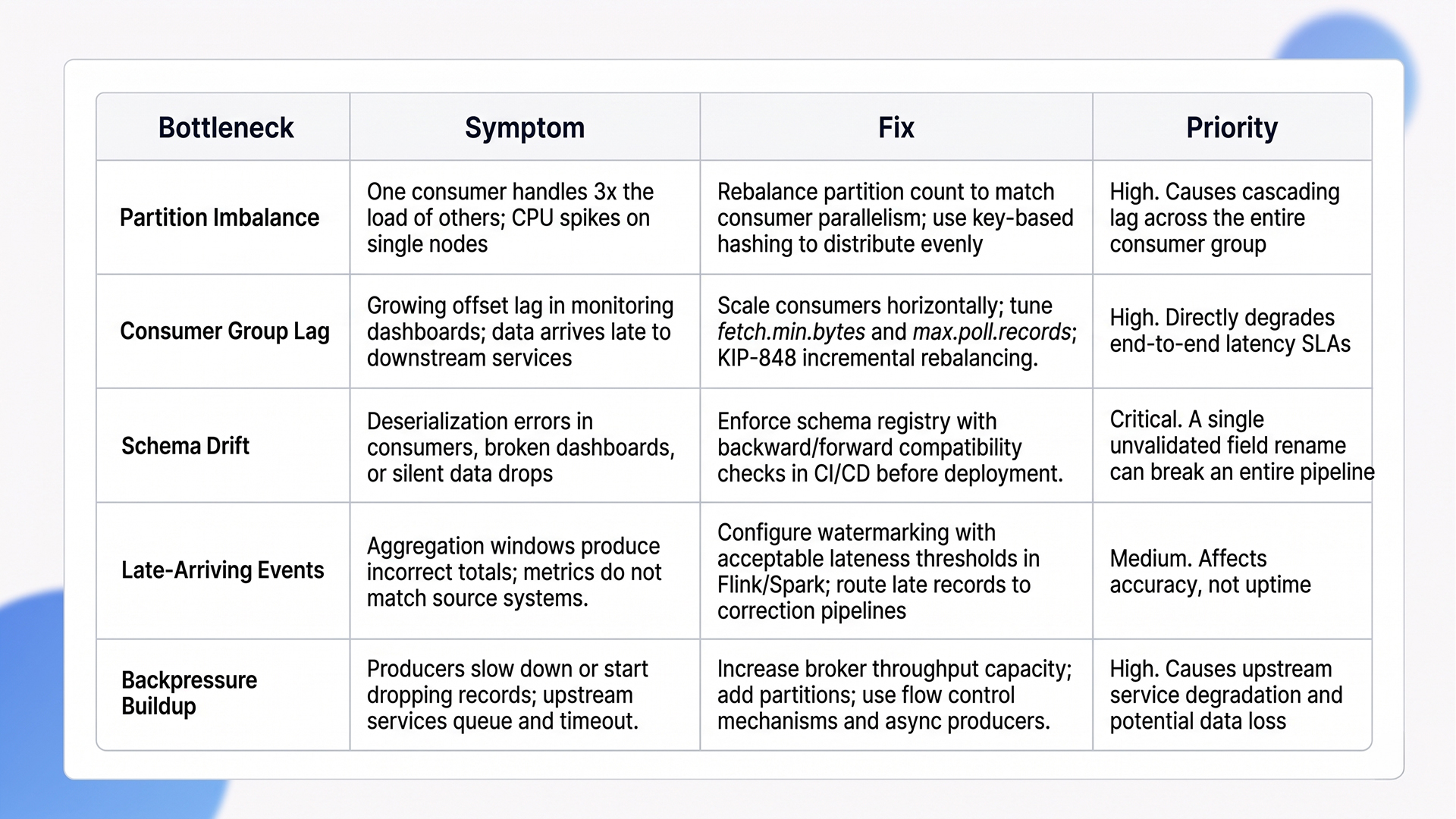
1. Managing Latency and Scale
Partition count should match consumer parallelism. Under-partitioning creates hot spots where a single consumer handles a disproportionate load. Over-partitioning wastes resources and increases coordination overhead across the cluster.
Kafka 4.0’s new consumer group protocol (KIP-848) eliminates the “stop-the-world” rebalance problem that plagued large deployments for years. Before this update, adding or removing a consumer triggered a full rebalance that paused all consumers in the group.
On a 50-partition topic with 10 consumers, that rebalance could take 30 seconds or more. KIP-848 makes rebalances incremental, which means low latency is no longer at risk every time the consumer group membership changes.
2. Ensuring Accuracy in Real-Time Insights
Delayed events and late-arriving data break aggregation windows. Without a strategy for handling out-of-order records, real-time insights become unreliable, and downstream dashboards show numbers that do not match source systems.
Watermarking strategies in Flink and Spark define acceptable lateness thresholds. Records arriving after the threshold are either discarded or routed to a correction pipeline. Schema registries (Confluent Schema Registry, AWS Glue Schema Registry) prevent broken pipelines by enforcing contract compatibility between producers and consumers.
Every schema change goes through validation before reaching production. Teams that skip schema governance pay for it later in hours of debugging pipeline failures caused by a single field rename.
Conclusion
Real time data processing is the baseline infrastructure for any organization that treats data as a competitive input. The right streaming data architecture, paired with proven real-time analytics tools, turns raw event streams into operational advantages that batch systems cannot match. With 90% of IT leaders increasing their data streaming investments in 2025, the gap between streaming-first organizations and batch-dependent ones will only widen.
Let’s talk about upgrading your data infrastructure with Ariel Software Solutions.
Frequently Asked Questions
1. What is the difference between batch and real time data processing?
Batch processing collects data over a set period and processes it in scheduled chunks. Real time data processing analyzes records the instant they arrive. The core difference is latency: batch delivers insights hours later, while real-time systems respond in milliseconds, enabling faster operational decisions and immediate anomaly detection.
2. Which tools are best for streaming data architecture?
Apache Kafka (especially version 4.0 with KRaft) and Apache Flink are the open-source standards for high-volume stream processing. Redpanda offers a Kafka-compatible alternative with lower latency on smaller footprints. For managed cloud options, AWS Kinesis, Google Cloud Pub/Sub, and Azure Stream Analytics handle scalable data ingestion without dedicated infrastructure teams.
3. How does real time data processing improve customer experience?
It enables instant personalized recommendations and zero-delay transaction processing. By analyzing user behavior the moment it happens, businesses adjust services on the fly. This speed helps brands deliver relevant digital experiences and resolve support tickets before frustration builds, directly reducing churn.
4. What are the main challenges of an event-driven architecture?
The primary difficulties include maintaining low latency during sudden data spikes, ensuring data consistency with late-arriving events, and managing infrastructure costs at scale. Integrating legacy databases into a continuous event-based flow without causing system downtime remains another frequent pain point for engineering teams.
5. Can small businesses benefit from real-time insights?
Yes. Cloud-native platforms offer flexible pricing that makes advanced real-time analytics tools accessible at smaller scale. Small businesses use these systems for live inventory tracking, targeted marketing, and immediate website performance monitoring without large upfront infrastructure investments or dedicated streaming engineers.
6. How has Kafka 4.0 changed real time data processing in 2026?
Kafka 4.0 removed ZooKeeper entirely and introduced KRaft as the sole metadata system. This raised the partition limit to 1.9 million per cluster, made topic operations faster, and eliminated the stop-the-world consumer rebalance problem. Teams report up to 40% faster cluster setup and 20% lower infrastructure costs after the migration.