Key Takeaway: Microservices split applications into independent, self-contained services that deploy and scale separately. 85% of enterprises reported using this architecture pattern in a 2022 Solo.io survey. But industry analysis of CNCF data shows 42% of those organizations are already consolidating services back into larger units. The right choice depends on team size, operational maturity, and actual scaling needs.
The global microservices architecture market reached $7.45 billion in 2025, a 20.9% year-over-year jump from $6.27 billion in 2024, and is projected to hit $18.72 billion by 2030. That growth tells one side of the story. The other side: Amazon Prime Video consolidated a distributed serverless workflow into a single ECS task and cut infrastructure costs by 90%. The technology is clearly maturing, but so is the industry’s understanding of where it fits and where it doesn’t.
This guide will break down what microservices are, how the architecture works under the hood, the real microservices architecture benefits and trade-offs, and when this pattern actually makes sense for your team in 2026.
What Are Microservices and How Does the Architecture Work?
What are microservices? They are an architecture pattern where an application is broken into small, independently deployable services, each responsible for a single business function and connected through APIs or messaging queues. Each service runs its own database and deployment pipeline.
That distinction matters because it explains the core problem microservices solve. In a monolith, every feature lives inside a single codebase. Change one component, and you redeploy the entire application.
Every team waits in the same release queue. Microservices remove that coupling. A payment service, a notification engine, and a user authentication module each operate as standalone units with separate codebases, separate data stores, and separate release cycles.
1. The Core Structure of Microservices Architecture
Each microservice owns one business function and one data store. That boundary is non-negotiable. The moment two services share a database, you reintroduce the coupling that microservices exist to eliminate.
The infrastructure layer supporting this includes API gateways (routing external traffic to the correct service), service registries (tracking which services are live and at what addresses), message brokers like Kafka or RabbitMQ (handling async communication), and container orchestration platforms like Kubernetes (managing deployment, scaling, and health checks across all services).
Without these components, running microservices in production becomes unmanageable at any real scale because there’s no automated way to track, route, or recover hundreds of independently deployed processes.
2. How Services Communicate in a Distributed System
Services talk to each other through two primary patterns, and choosing the wrong one for a given workload is one of the most common early mistakes teams make.
Synchronous communication (REST APIs, gRPC) works when a service needs an immediate response. gRPC outperforms REST for internal service-to-service calls because it uses binary serialization (Protocol Buffers) instead of JSON, reducing payload size and parse time. Use synchronous calls when the calling service cannot proceed without the response.
Asynchronous communication through event-driven architecture (Kafka, RabbitMQ) fits workloads where services don’t need instant replies. Order placement is a textbook example: the order service publishes an event, and inventory, billing, and notification services each consume it independently.
This pattern decouples services at the temporal level, meaning one slow service doesn’t block the rest of the chain. For workloads with variable demand, async patterns reduce cascading failures and allow each service to process at its own throughput capacity.
3. What Happens When You Deploy a Microservice
The deployment lifecycle for a single microservice follows a clear path: code commit triggers a CI/CD pipeline, the pipeline builds a containerized image, and Kubernetes orchestrates the rollout with zero downtime using rolling updates or blue-green deployment strategies.
“Building resilient multi-tenant platforms requires choosing the right service boundaries to ensure performance, as we break down in our expert guide, Microservices for SaaS: Building Highly Scalable Cloud Products”.
The practical difference from monolith deployment is significant. In a monolith, a single change to the checkout module forces a full application redeploy, which blocks every other team waiting to release. With microservices, one team ships one service without touching anything else. Independent deployment removes that bottleneck entirely, and it’s the reason large engineering organizations with 10+ teams gravitate toward this pattern.
Understanding these structural mechanics is the foundation. The next question is what practical advantages this architecture delivers in production environments.
Microservices Architecture Benefits That Actually Matter in 2026
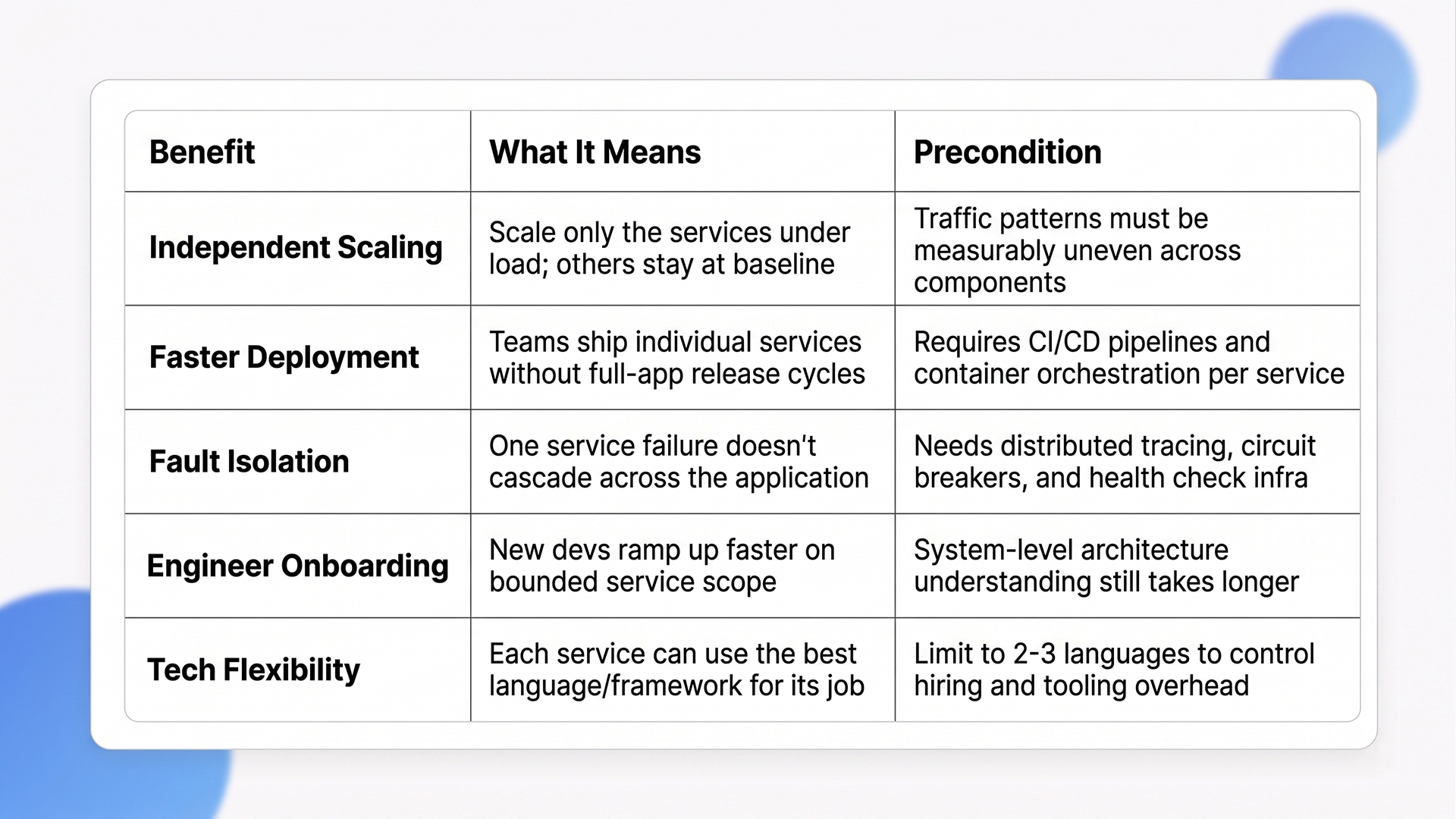
Microservices architecture benefits include independent scaling, faster deployment cycles, fault isolation, and per-service technology choice. These advantages compound for organizations with large engineering teams and complex product requirements, but each one comes with an operational precondition that determines whether the benefit materializes or becomes overhead.
1. Independent Scaling and Deployment Speed
Uber reported reducing feature integration time from 3 days to 3 hours after moving to microservices. That speed gain came from teams deploying individual services without waiting for a coordinated full-application release cycle.
Scaling becomes surgical. A payment service handling 50x compute during peak hours scales independently while the user profile service runs at baseline capacity. You stop paying for scale components that you don’t need.
This selective scaling is the primary cost argument in favor of microservices for high-traffic applications, but it only pays off when your traffic patterns are genuinely uneven across components. If all services scale together anyway, you’ve added orchestration complexity for no measurable gain.
2. Faster Onboarding for New Engineers
New developers working within a bounded service mesh context become productive faster than those dropped into a massive monolithic codebase. The focused scope of each service reduces cognitive load and shortens ramp-up time.
This is especially valuable for teams hiring across data engineering, ML, and backend operations. A new ML engineer can understand the inference service in a few days without needing to grok the entire application.
The catch: onboarding speed for individual services improves, but understanding the system-level architecture (how services interact, fail, and recover) takes longer than in a monolith, where everything is visible in one codebase.
3. Fault Isolation and Resilience
If one service fails, the rest of the application keeps running. Circuit breaker patterns, service mesh retries, and traffic management tools like Istio and Linkerd prevent cascading failures.
A payment service going down shouldn’t take product search offline with it. That isolation is the single biggest operational win for teams managing user-facing applications with strict uptime requirements.
The prerequisite: you need distributed tracing, centralized logging, and health check infrastructure in place before fault isolation works as intended. Without observability, a failure in one service becomes invisible rather than isolated.
4. Technology Flexibility Per Service
Each service picks its own language, framework, or database. An ML inference service runs Python while the core backend runs Java. A real-time notification engine uses Go. This polyglot advantage is critical for teams building AI-powered features into existing platforms because ML workloads have fundamentally different runtime and library requirements than transactional backend services.
One word of caution: polyglot freedom sounds appealing, but every additional language in your stack multiplies the hiring, tooling, and debugging surface area. The practical sweet spot for most organizations is 2-3 languages across the entire service fleet, not a different language per service.
Quick Glance: Microservices Architecture Benefits
These benefits are real for teams that understand what microservices at the operational level are, but they come with costs that most generic guides skip over. Here’s what the trade-off picture actually looks like.
The Real Costs and Trade-Offs of Microservices (Microservices vs Monolith)
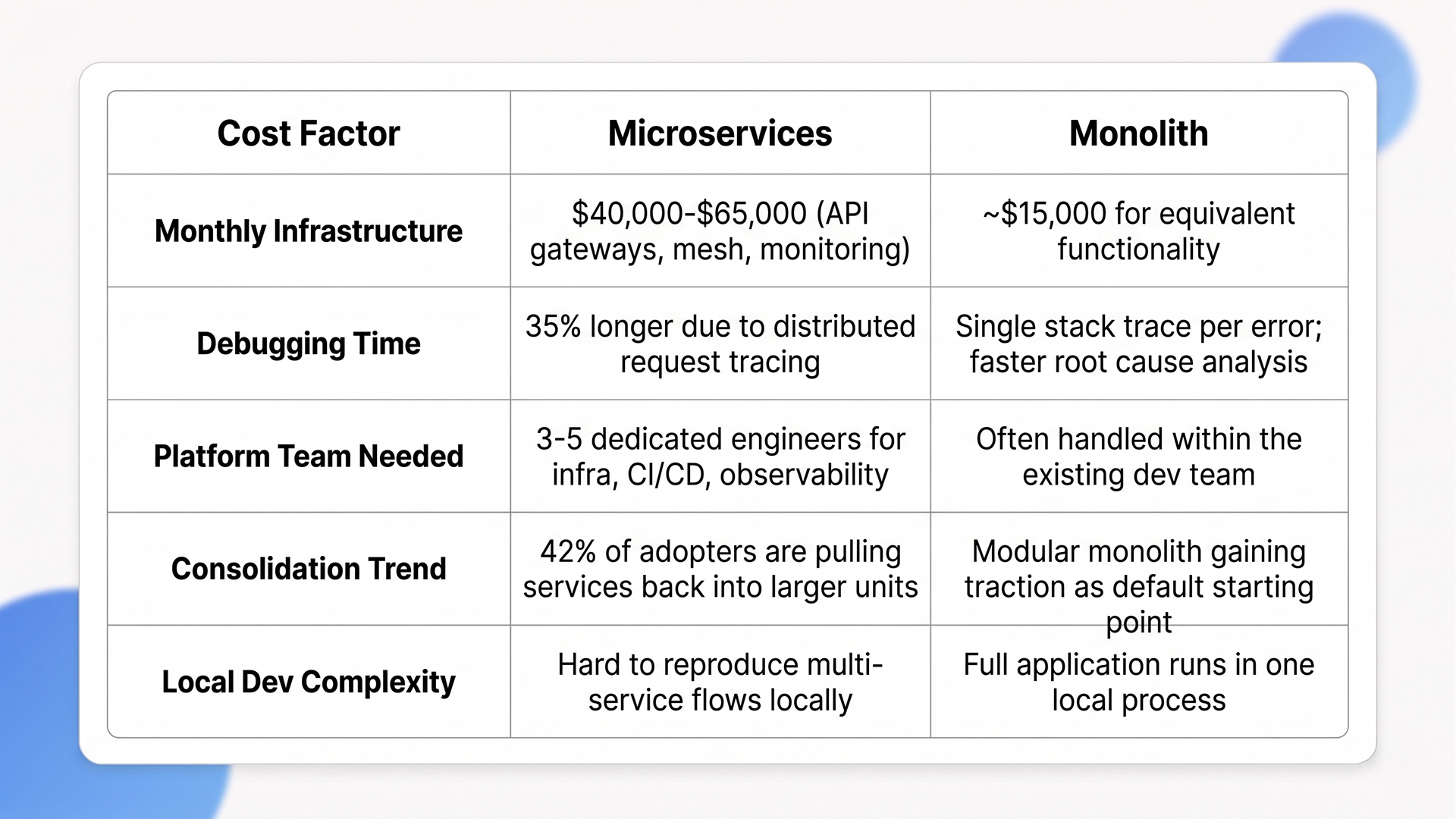
Microservices vs monolith is not a question of which is better. It is a question of which trade-offs your team can absorb. Industry estimates suggest microservices add 3.75x to 6x infrastructure cost, 35% more debugging time, and significant operational overhead compared to a monolith.
1. Infrastructure Costs Are 3.75x to 6x Higher.
Industry estimates place microservices infrastructure at $40,000 to $65,000 per month compared to roughly $15,000 per month for monoliths at equivalent functionality. That premium covers API gateways, load balancers, service mesh, distributed systems logging, and monitoring.
The hidden cost that catches most teams: platform engineering headcount. Running microservices at production grade typically requires a dedicated platform team of 3-5 engineers managing CI/CD pipelines, Kubernetes clusters, service mesh configuration, and observability tooling.
For teams under 20 engineers total, that platform overhead often represents 15-25% of the entire engineering budget spent on infrastructure rather than product features.
2. Debugging Takes 35% Longer in Distributed Systems.
Teams spend an average of 35% more time debugging in microservices architectures compared to modular monolith setups, according to analysis published on Java Code Geeks. The primary culprits: distributed request flows that span multiple services, inconsistent logging formats across teams, and difficulty reproducing production issues in local development environments.
This is where most teams underestimate the real cost of microservices. A bug in a monolith produces a single stack trace. A bug across three microservices produces three partial traces that need to be correlated through a distributed tracing tool like Jaeger or Zipkin. If that tooling isn’t set up correctly, debugging a single request path can take hours instead of minutes.
“To optimize performance across complex Azure and AWS stacks, engineering leaders should refer to our technical walkthrough, Cloud Application Development: A Guide to Building Resilient Global Systems.”
3. The 42% Consolidation Trend
Industry analysis of CNCF survey data indicates that 42% of organizations that adopted microservices are now consolidating services back into larger deployable units. The primary drivers: debugging complexity, operational overhead, and network latency.
The most cited case: Amazon Prime Video’s monitoring team consolidated a distributed serverless workflow (AWS Step Functions and Lambda) into a single ECS task, cutting infrastructure costs by 90%. Important nuance: this was a serverless-to-consolidated-service move, not a full microservices-to-monolith migration.
The team moved from a Step Functions orchestration to a single process, which is still technically a microservice running on ECS. The lesson isn’t that microservices failed. It’s the wrong distribution granularity that created unnecessary overhead for that specific workload.
Quick Glance: Real Costs of Microservices vs Monolith
These cost and complexity realities define the microservices vs monolith decision. The question isn’t a theoretical preference. It’s which trade-offs your team can absorb.
When to Use Microservices and When to Avoid Them
Use microservices when your engineering team exceeds 50 people, components need genuinely independent scaling, or compliance mandates physical service separation. For most other scenarios, a modular monolith with selective service extraction is the stronger option in 2026.
A) Use Microservices When
- Team size exceeds 50+ engineers working on the same product, where monolith merge conflicts and release coordination become the primary bottleneck
- Components need genuinely independent scaling (e.g., payment processing at 50x compute vs. other services at baseline), and traffic patterns are measurably uneven across the application.
- Regulatory isolation requires physical separation (PCI compliance for payment services, HIPAA for health data), where data boundaries must be enforceable at the infrastructure level.
- Polyglot requirements exist (ML models in Python, core backend in Java, real-time services in Go) and cannot be solved within a single runtime.
- Multiple teams need full deployment autonomy without blocking each other’s release cycles, and those teams are structured around distinct business domains.
B) Use a Modular Monolith Instead When
The industry consensus for 2025-2026 recommends a modular monolith core plus 2-5 extracted services for specific hot paths.
- Team is under 20 engineers, where the coordination overhead of microservices outweighs the deployment independence they provide
- DevOps microservices maturity is limited (small platform engineering capacity), making it difficult to operate the distributed infrastructure reliably
- Priority is cost efficiency and development velocity over maximum horizontal scaling, which applies to most early-stage and mid-stage products.
Shopify proves the modular monolith works at a massive scale: their application runs 2.8 million lines of Ruby code and handled 32 million requests per minute during Black Friday peak.
The takeaway: monolith doesn’t mean small. It means a single deployable unit with strong internal module boundaries.
“Transitioning from a monolith involves strategic extraction patterns like the Strangler Fig, a process we document in our guide to Legacy Application Modernization: Transforming Monoliths into Modern Services.”
C) The Hybrid Approach for 2026
The most common 2026 strategy: start with a modular monolith, then selectively extract services when business justifies it. This is the “Strangler Fig Pattern,” and it treats microservices as an optimization applied to specific components rather than a default starting architecture.
The extraction criteria should be concrete: extract a service when a component has different scaling requirements, a different release cadence, or a different team ownership boundary. The core question of what microservices are solving for your specific product should drive every extraction decision. “It would be cleaner as a separate service” is not sufficient. Operational cost always increases with extraction.
With the decision framework covered, here’s how a team with deep cloud-native development experience approaches this at the implementation level.
How Ariel Software Solutions Designs and Deploys Microservices Architecture Built for Scale
Ariel Software Solutions addresses the exact problems that cause microservices projects to fail: wrong-sized service boundaries, missing observability, premature distribution, and infrastructure cost spirals. With 15+ years of production delivery and 1,100+ completed projects across healthcare, logistics, real estate, and financial services, our engineering teams have seen what breaks at scale and what holds.
Every engagement starts with an architecture assessment. We evaluate your team size, traffic patterns, compliance constraints, and DevOps maturity before recommending a pattern. If a modular monolith delivers better speed and cost efficiency for your stage, that’s the recommendation. If multi-team autonomy and regulatory isolation demand full microservices, we build it with distributed tracing, centralized logging, and CI/CD pipelines wired in from day one.
- Architecture assessments that prevent premature distribution and right-size service boundaries to your actual scaling needs
- Full-spectrum builds: modular monolith, hybrid extraction (Strangler Fig), or production-grade microservices with observability built in
- Post-launch support, including AI model tuning, performance monitoring, and infrastructure cost optimization across Azure and AWS stacks
Let’s talk about your architecture decision. Book a technical walkthrough with Ariel’s engineering team.
Conclusion
What are microservices? A powerful architecture pattern for organizations with the team size, operational maturity, and scaling needs that justify the added complexity. For most teams under 50 engineers, a modular monolith with selective service extraction delivers better speed, lower cost, and cleaner maintainability.
The right answer in 2026 isn’t which pattern is more modern. It’s which one your organization can operate sustainably and improve on as you grow.
Let’s connect with Ariel Software Solutions to get an architecture assessment matched to your team, product, and growth trajectory.
Frequently Asked Questions
1. What are microservices in simple terms?
What are microservices? They are a software architecture pattern where an application is built as a collection of small, independent services. Each service handles one business function (like payments or user authentication), runs its own database, deploys independently, and communicates with other services through APIs or message queues.
2. What is the difference between microservices and monolith architecture?
A monolith is a single deployable unit where all code lives together. Microservices vs monolith: microservices split the application into independently deployable services, each with its own database and deployment pipeline. Monoliths are simpler to build and debug. Microservices offer independent scaling but add infrastructure cost and distributed system complexity.
3. When should a company use microservices architecture?
Use microservices when your engineering team exceeds 50 people, different components need independent scaling, regulatory compliance requires physical service separation, or multiple teams need deployment autonomy. For smaller teams or early-stage products, a modular monolith fits better with lower cost and simpler operations.
4. How much more do microservices cost compared to a monolith?
Industry estimates place microservices infrastructure costs at 3.75x to 6x higher than monoliths for equivalent functionality. At enterprise scale, monoliths cost roughly $15,000/month vs. $40,000 to $65,000/month for microservices when factoring in API gateways, service mesh, distributed logging, monitoring, and additional platform engineering salaries.
5. Why are companies moving back from microservices to monoliths?
Industry analysis of 2025 CNCF data suggests 42% of organizations that adopted microservices are consolidating services back into larger units. Primary reasons: debugging complexity (35% more time spent), operational overhead, network latency, and infrastructure costs that outweigh benefits for most use cases.
6. What is a modular monolith, and how is it different from microservices?
A modular monolith is a single deployable application structured with strict internal module boundaries by business domain. Modules communicate through in-process calls rather than network requests. It provides architectural clarity similar to microservices without the operational cost. Shopify runs on a modular monolith handling 32 million requests per minute at peak.


