Most enterprise application modernization programs do not fail because the technology is wrong. They fail because the program was scoped as a technology project when it was actually an operating model change.
Across 16 years of delivering modernization work at Ariel, the same pattern repeats. A monolith is identified as the bottleneck. A target architecture is sketched. A multi-year roadmap is approved. Eighteen months in, the legacy system is still running production, the new microservices are partially deployed, ownership is unclear, and the budget is two-thirds spent. The platform isn’t broken. The execution model is.
The application modernization strategy patterns that actually hold up at scale aren’t the ones that look cleanest on a slide. They are the ones engineered around a hard truth: legacy systems are load-bearing for the business while you’re rebuilding them, and every architectural decision has to respect that.
Key Takeaways
- Modernization fails operationally before it fails technically. Plan ownership, governance, and team structure first.
- Big bang rewrites carry roughly 70% failure rates. Incremental patterns like Strangler Fig consistently outperform them.
- 60 to 80% of enterprise IT spend goes to keeping legacy systems running. Modernization isn’t optional, it’s a cost-control move.
- The 7Rs framework helps choose the right approach per application. Not every legacy system needs to be rebuilt.
- Data migration, observability gaps, and team capability are the most underestimated cost lines.
- Cloud-native, microservices, and API-first all sound similar but solve different problems. Match the pattern to the bottleneck.
- Modernization without a sustained operating model just relocates technical debt instead of removing it.
Why Modernization Programs Stall, Even When the Tech Is Right
Modernization is no longer a discretionary line item. Gartner forecasts worldwide IT spending to reach $5.43 trillion in 2025, with enterprise software growing 14% year on year. Most of that growth is going into AI and cloud-native platforms that legacy systems cannot host. The result is a forced choice: modernize the foundation or watch new investments pile up on top of stacks that cannot support them.
McKinsey’s recent analysis frames the same pressure differently. Companies described as “strained transformers” are funding modernization and AI but adding the new capabilities on top of existing systems, which compounds technical debt rather than reducing it. The legacy footprint never shrinks. Run costs rise. ROI flattens. This is the most common mode of legacy system modernization failure we see in the field, and it has nothing to do with the technology choice.
The deeper failure mode is structural. Programs are scoped against an architectural target (microservices, cloud-native, event-driven) without scoping the operating changes that target requires:
- Service Ownership
- Data Governance
- Observability Discipline
- Deployment Cadence
- On-Call Coverage
The architecture diagram is the easy part. The operating model is what determines whether the architecture survives in production.
The 7Rs Framework: Choosing the Right Pattern per Application
Most enterprises are modernizing a portfolio, not a single system. Treating every application the same way is one of the most expensive mistakes we see. The 7Rs framework, originally formalized by AWS and now widely adopted across the industry, gives a usable decision lens.
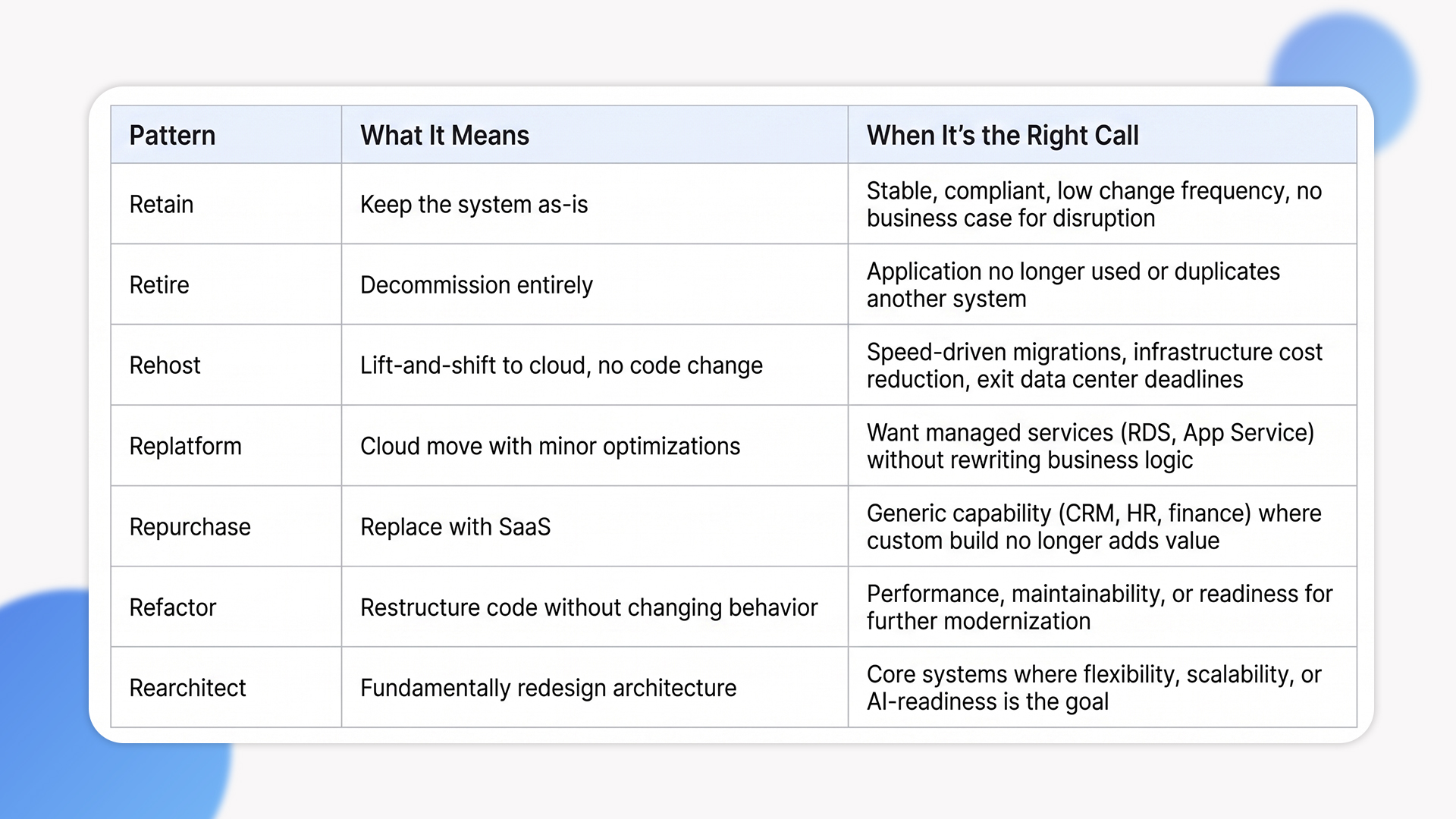
The mistake we correct most often is portfolio overreach. Teams default to rearchitect because it sounds the most ambitious, then drown in scope when 60% of the portfolio could have been retained or rehosted with no strategic loss. A useful application modernization strategy starts by sorting the portfolio honestly: which systems actually need transformation, and which just need to be moved or left alone.
Strangler Fig: The Pattern That Actually Works at Scale
If there is a single pattern that has earned its reputation in enterprise modernization, it is the Strangler Fig pattern. Coined by Martin Fowler, the idea is to wrap the legacy system in a routing facade and progressively replace its functionality with new services, one capability at a time, until the legacy system can be decommissioned.
The data behind this pattern is unambiguous. Gartner estimates that 70% of full rewrites exceed budget or timeline. Project data from incremental migration practitioners shows roughly 40% lower failure rates compared to big-bang rewrites, driven by smaller, reversible deployments and continuous feedback. The pattern reduces risk because it never asks the business to take the cutover hit all at once.
That said, Strangler Fig isn’t a free pattern. It introduces specific failure modes we’ve seen repeatedly in the field, and they are the reason most public case studies leave them out.
Failure mode 1: The Distributed Monolith
Teams extract services from the legacy system but don’t introduce a proper Anti-Corruption Layer. The new services end up calling the legacy database directly, inheriting its schema, locking, and data model. The result is a set of microservices that are still tightly coupled to the legacy backend. The monolith is “strangled” in name only, and the technical debt has just been redistributed across more deployment units.
Failure mode 2: Premature termination
Modernization is multi-year work. Teams reach the 60% mark, the new services are handling most of the traffic, and the program loses funding or sponsorship before the legacy system is fully retired. Now the organization carries both stacks indefinitely, which is the worst of both worlds: full legacy maintenance plus full microservices operational overhead.
Failure mode 3: Data sovereignty drift
If a new service still depends on the monolith’s database for every read, it isn’t a service, it’s a wrapper. We enforce data sovereignty during extraction, using Change Data Capture or dual-write patterns to keep data in sync without coupling the new service to the legacy data model. This is one of the highest-leverage decisions in the entire program, and the one most often deferred.
Failure mode 4: Flat-line observability
In a monolith, observability is mostly a logging problem. In a partially-migrated environment, it becomes a distributed tracing problem with two stacks. Teams that don’t invest in OpenTelemetry, structured logs, and unified dashboards from day one lose the ability to diagnose incidents quickly, which is exactly when business confidence in the program collapses.
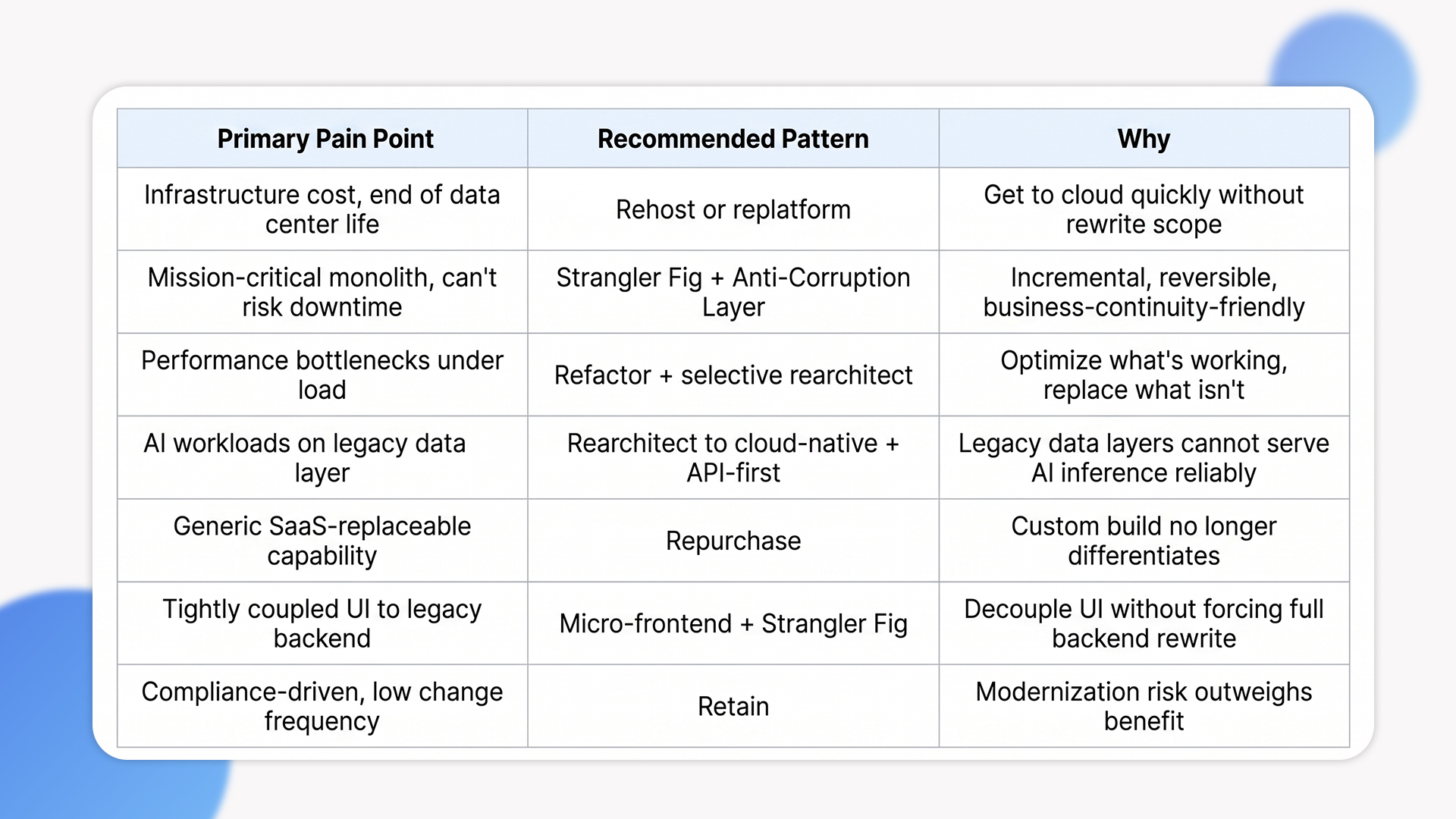
Choosing the Right Modernization Pattern: A Decision Lens
Different bottlenecks call for different patterns. The table below summarizes how we map common pain points to the right modernization approach in client engagements.
The Trade-offs Most Modernization Posts Skip
Here are the costs that don’t appear in the original business case but determine whether the program lands on time and on budget.
Data migration is harder than the architecture
Legacy systems use outdated schemas, inconsistent references, and undocumented business logic embedded in stored procedures. Experian research shows only 46% of data migration projects deliver on time and 36% on budget. The fix isn’t more planning, it’s an incremental migration approach with automated validation at each step. We rarely lift data in a single event. We move it in batches with automated reconciliation comparing old and new records, so any inconsistency is caught the same day rather than the same quarter.
Observability gaps cost more than the migration
In monoliths, you can attach a debugger to one process. In a microservices estate mid-migration, an incident may span four services, two databases, a message bus, and a legacy facade. Without distributed tracing and unified logging in place before extraction begins, mean-time-to-recovery climbs sharply. We’ve seen organizations spend more engineering hours on incident triage during migration than on the migration itself, simply because observability was deferred to phase two.
The institutional knowledge problem
Every legacy system has business rules embedded in code that no current employee fully understands. 60% of COBOL-dependent organizations cite finding skilled developers as their single biggest operational challenge, and the same pattern shows up in older .NET WebForms, classic ASP, and on-premise Java EE estates.
Modernization isn’t just rewriting, it’s re-discovery. We treat business rule extraction as its own workstream, with documentation and acceptance tests captured before any code is rewritten. Skipping this step is how migrated systems silently lose edge-case logic that production depended on.
Team capability is the longest pole
Microservices, Kubernetes, event-driven architectures, and modern CI/CD pipelines require different skills than traditional enterprise development. Hiring is one option, but building in-house capability through pairing, embedded engineering, and structured handoff is what makes the modernized system sustainable post-program.
Compounding cost of doing nothing
The least-discussed trade-off is what happens when modernization keeps getting deferred. Industry data from Gartner and Deloitte consistently shows enterprises allocating 60 to 80% of their IT budget to maintaining existing systems, and that ratio worsens roughly 10 to 15% annually after end-of-warranty. The modernization business case isn’t just about new capability. It’s about freeing the budget that’s currently locked up in keeping the lights on.
When NOT to Modernize (Yet)
We’ve actively walked clients away from modernization in three situations.
- The legacy system is stable, compliant, and infrequently changed
Banking core systems, regulated medical devices, embedded controllers. If the system runs reliably, has unbroken audit trails, and rarely changes, the migration risk often outweighs the benefit. Retain is a legitimate strategy, not a default failure.
- The organization isn’t ready to operate the target architecture
Microservices in production require service ownership, on-call coverage, deployment discipline, and observability investment. Without those, the modernized system decays faster than the legacy one. We coach clients to build the operating capability before, not after, the architecture lands.
- There is no clear business outcome attached to the program
“Move to microservices” is not an outcome. “Reduce time-to-feature from 8 weeks to 2 weeks” is. “Cut infrastructure cost by 40%” is. “Enable AI inference on production data” is. Programs scoped without measurable outcomes drift, and drifting modernization programs are how technical debt gets repackaged rather than removed.
How Ariel Approaches Modernization Programs
We don’t lead with target architecture diagrams. We start with the operating reality: what’s running today, who owns it, what’s slowing the business down, and what the team can actually sustain.
Most engagements begin with portfolio assessment. We classify each application against the 7Rs, identify the highest-leverage candidates for transformation, and pressure-test the business case. Some applications get retired. Some get rehosted with minimal change. The handful of systems that genuinely justify rearchitecting are sequenced based on business value, technical risk, and team readiness.
From there, the engineering work follows the Strangler Fig pattern in most cases:
- Deploy the routing facade early. This becomes the entry point for traffic and the foundation for incremental extraction.
- Extract one low-risk capability into a new service. Start with a contained, well-understood part of the system to validate the pattern before scaling it.
- Prove the deployment, observability, and rollback story. Confirm the operational mechanics work end-to-end before extending the approach across more services.
Every architectural decision is documented. Every new service ships with runbooks, ownership, and on-call coverage. The handover happens continuously, not at the end, because a modernization that the client team cannot operate is a modernization that fails six months later.
For organizations where AI readiness is part of the modernization business case, the architectural constraints go deeper than most programs plan for. Legacy platforms built for deterministic workloads routinely fail under AI inference demands, not because the models are wrong but because the underlying data layer, scaling model, and observability infrastructure were never designed for probabilistic, high-throughput compute. Similarly, API sprawl and fragmented reporting logic compound the problem by creating ambiguous interfaces that AI agents cannot reliably reason across, turning what should be an integration problem into a re-architecture problem.
Planning a modernization program and want a delivery-grade assessment, not a vendor pitch?
Our team has run portfolio assessments and Strangler Fig migrations across enterprise and mid-market clients for 16 years. We’ll review your current estate, identify the highest-leverage candidates, and give you an honest path forward.
Frequently Asked Questions
1. How long does enterprise application modernization take?
It depends on portfolio size and pattern choice. Phased Strangler Fig migrations on a single mission-critical system typically run 9 to 18 months, with measurable improvements visible within the first 90 days. Multi-system portfolio modernizations are usually 2 to 4 year programs, structured as a sequence of smaller, individually scoped engagements rather than a single multi-year project.
2. What’s the biggest cost most teams underestimate?
Data migration, observability, and team capability, in that order. The architecture work is usually well-scoped. The data validation, distributed tracing setup, and team upskilling are routinely underestimated by 30 to 50% in initial business cases.
3. Should we use a big-bang rewrite or incremental migration?
Almost always incremental. Big-bang rewrites carry roughly 70% rates of budget or timeline overrun. Strangler Fig and similar incremental patterns reduce that risk substantially because the legacy system keeps running while the new one is built around it. Big-bang is only defensible when the legacy system is so brittle that incremental extraction is genuinely impossible, which is rare.
4. Does modernization always mean cloud and microservices?
No. Cloud and microservices are common targets, but not universal. Some applications are best served by replatforming to managed services without breaking them into microservices. Others belong on SaaS replacements. The right application modernization strategy matches the pattern to the bottleneck, not the other way around.
5. Can Ariel handle modernization end-to-end?
Yes. We cover portfolio assessment, target architecture design, Strangler Fig execution, data migration, CI/CD pipeline setup, observability tooling, and team enablement. Get in touch to scope your program.
The Decision That Actually Matters
The strongest enterprise application modernization programs aren’t the ones with the most ambitious architecture. They are the ones that match pattern to problem, sequence work against business value, and build operating capability alongside the new platform.
Pick the right pattern for each system. Invest in observability and data discipline early. Treat institutional knowledge extraction as a workstream, not an afterthought. Build the operating model before the production cutover, not after. The architecture follows from those decisions, not the other way around.
Ready to scope a modernization program built on delivery reality, not vendor templates?
Book a free consultation with Ariel’s modernization team. We’ll assess your current estate, map the right patterns, and give you a sequenced roadmap your team can actually deliver against.