Legacy modernization fails in predictable ways. Scope balloons. Discovery is rushed. Critical business logic that lived only in someone’s head turns out to be load-bearing. The cutover that was supposed to take a weekend slips into a quarter. By month nine, the project is 4x over budget and someone is asking who approved the original scope. None of these failures are random. Each one traces back to a specific risk that wasn’t managed before it surfaced.
Kyndryl’s 2025 State of Mainframe Modernization survey reports ROI ranging from 288% for mainframe-resident modernization to 362% for off-mainframe migrations when projects are scoped and executed well. The same data shows that when projects fail, they consistently fail for the same reasons: skipped discovery, missing rollback paths, untested data migration, and tribal knowledge that left the building with the last engineer who understood the system. The difference between the 288% ROI and the 4x overrun isn’t the technology. It’s the risk-reduction discipline applied before any code is touched.
This guide walks through the risk-reduction approach we apply on every legacy system modernization services engagement we apply at Ariel as part of our legacy system modernization services, the specific disciplines that prevent the most common failure modes, and the operating principles that make migrations land cleanly instead of stalling at month nine.
Key Takeaways
- Modernization failures are predictable. Scope drift, skipped discovery, missing rollback paths, and tribal knowledge loss account for the dominant share.
- Risk reduction is sequenced into the engagement from sprint one. It’s not a phase, it’s a delivery discipline applied continuously.
- Discovery is the single highest-leverage investment in any modernization project. Budget problems almost always trace back to discoveries that got cut short.
- Rollback paths protect every step. Big-bang cutovers consistently fail; incremental migrations with reversible stages consistently land.
- Tribal knowledge capture has to happen before key engineers rotate off the project, not after. Documentation is a sprint deliverable.
- Parallel-run validation catches data and behavior drift that test environments miss. Plan for the parallel-run cost as a known line item, not a surprise.
- Cutover is the riskiest moment in any modernization. Treat it as a structured event with rehearsals, named go and no-go criteria, and documented backout.
Why Most Legacy Modernization Projects Fail at the Same Points
The cost of failed modernizations is well documented. Tech-Stack’s 2026 analysis of legacy projects observed that a USD 500K modernization often becomes USD 2M nine months in, with budget problems almost always tracing back to skipped discovery. McKinsey’s research reinforces the pattern: 70% of Fortune 500 companies still operate software over two decades old, and the projects that successfully replace those systems share a specific operational discipline that the projects that stall consistently miss.
Across legacy application modernization services engagements, the failure modes cluster around six recognizable risks. Each one has a defined operating discipline that prevents it. The risk-reduction approach isn’t a phase you run before the project starts; it’s a delivery practice applied continuously across the engagement.
The Six Risks That Define Every Legacy Modernization Project
Risk 1: Tribal knowledge that walks out the door
Most legacy systems run on logic that lives in the heads of two or three engineers, not in documentation. When those engineers retire, change roles, or leave the project, the knowledge goes with them. Industry research suggests around 42% of critical business logic in legacy systems is at risk when key personnel leave, because the system is the documentation in most legacy environments.
Risk-reduction discipline: Tribal knowledge capture is a first-sprint activity, not a closing one. The discipline covers:
- Walk-through sessions with named engineers, recorded and transcribed.
- Architecture decision records produced as the team learns the system, not after the migration ships.
- Code archaeology before code translation.
The cost of an additional two weeks in discovery is small. The cost of discovering a missing business rule three months into rebuilding is large.
Risk 2: Scope creep from skipped discovery
Discovery is the cheapest part of the project. It’s also the part most teams compress to start building faster. The result is a project scope built on assumptions, which turn out to be wrong in week six and expensive to fix in month nine. The pattern is so consistent that it’s the single best predictor of whether a modernization will land cleanly or stall.
Risk-reduction discipline: Full discovery before the build commits. The work covers:
- Inventory every integration, every batch job, every report, every undocumented downstream consumer.
- Profile data quality across every source system.
- Identify every compliance and audit obligation that constrains the design.
Discovery typically runs 4 to 8 weeks for a meaningful enterprise system. Compressing it produces overruns that cost more than the time saved.
Risk 3: Big-bang cutovers that can’t be undone
Modernization projects that try to move from the legacy system to the new system in a single cutover consistently fail. The reasons vary: data migration that didn’t catch every edge case, downstream systems that depended on undocumented behavior, user workflows that broke in ways nobody anticipated. Once the cutover is irreversible, every problem becomes a production emergency.
Risk-reduction discipline: Incremental migration with rollback paths at every stage. The Strangler Fig pattern is the proven approach: route specific functionality from the legacy system to the new system one slice at a time, with the legacy system still available as fallback. Each slice is validated independently. Each cutover is reversible. The total elapsed time is longer than a big-bang approach would be in theory; in practice, big-bang approaches rarely ship on their original timeline.
Risk 4: Data migration that misses edge cases
Legacy data carries decades of accumulated inconsistency. Schema decisions made in 2003 that don’t fit current understanding. Workarounds that became permanent. Values that look correct in production but break the assumptions of the new system. The migration that works in staging frequently produces unexpected results in production because production data has shapes that staging data doesn’t capture.
Risk-reduction discipline: Treat data migration as continuous validation, not a single cutover event:
- Profile real production data, not sampled or synthetic data.
- Build automated reconciliation between source and target for every migrated record.
- Run parallel migrations against full data volumes before cutover.
- Verify data integrity continuously, not at a single validation checkpoint.
The parallel-run cost is real, but it’s smaller than the cost of discovering data inconsistency after cutover.
Risk 5: Performance regression in production
The new system performs well in test environments. Production traffic patterns are different. Real user volumes, real query mixes, real concurrent workloads surface bottlenecks that staging never exercised. Performance regressions in modernized systems are common and frequently surface late, when rolling back is expensive.
Risk-reduction discipline: Performance has to be measured before cutover, not after. The pattern that works:
- Load testing against production-realistic traffic profiles before cutover.
- Observability is designed in from the first sprint (distributed tracing, structured logging, named performance budgets) so regressions are detected immediately.
- Canary deployment patterns that route a small percentage of traffic to the new system first, validate behavior, then progressively increase the share.
- Performance budgets enforced as commit-blocking checks, not reviewed at the end of the project.
Risk 6: Compliance and audit gaps in the new system
Legacy systems often have years of accumulated compliance posture (audit trails, access logs, retention policies, regulatory approvals) that weren’t designed in but emerged through operational practice. Modernized systems sometimes lose this posture in the rebuild, with the loss surfacing during the first audit after cutover.
Risk-reduction discipline: Compliance is an architectural decision, not a phase-five task. The practice covers:
- Compliance and audit obligations mapped during discovery, not retrofitted after rebuild.
- Audit logging, access controls, and retention policies designed into the new architecture from sprint one.
- Regulatory review of the target architecture before development begins.
The cost of building compliance is small. The cost of adding it after the fact is high.
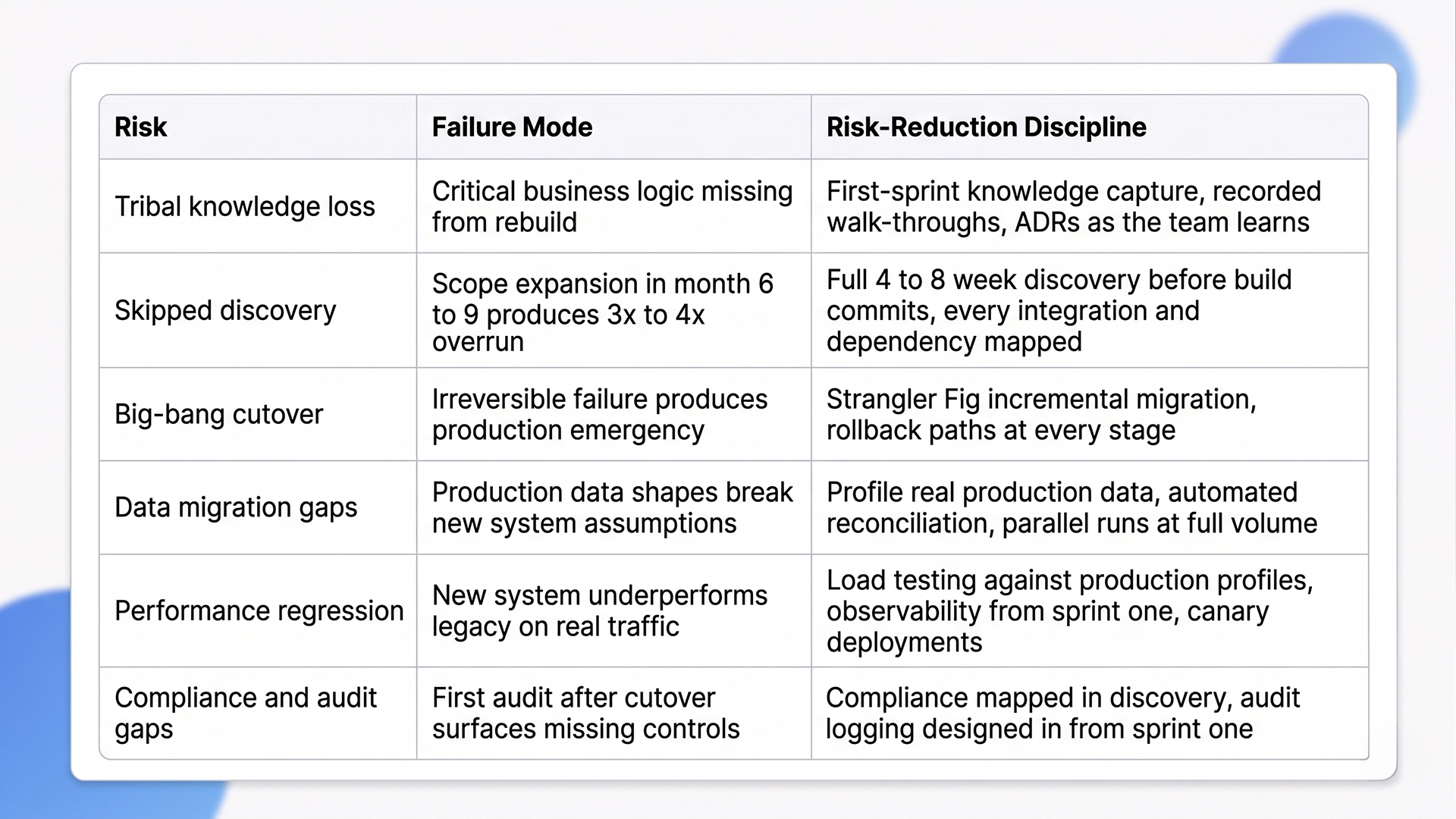
The Risk-Reduction Matrix We Apply on Every Engagement
The table below summarizes the six risks, the failure mode each one produces, and the operating discipline that prevents it. Treat it as the working framework we apply on every legacy software modernization company engagement.
How We Sequence Modernization Engagements
Risk reduction sits inside a delivery sequence that’s consistent across every engagement, regardless of which modernization pattern fits the system. The sequence is deliberate; reordering it is usually the source of the failures the disciplines above are designed to prevent.
Stage 1: Discovery and risk inventory
Four to eight weeks. Output is a detailed map of the existing system: every integration, every batch job, every undocumented dependency, every compliance obligation, every business rule expressed only in code. The risk inventory is built during discovery; if a risk doesn’t surface in discovery, it surfaces later as an overrun.
Stage 2: Target architecture and migration sequencing
Three to six weeks. The target architecture is designed against the discovery output, not against a default modernization pattern. The migration sequence (which slice moves first, which depends on which, where the rollback boundaries live) is mapped explicitly. The plan is structured so that each slice is independently shippable and independently reversible.
Stage 3: Incremental migration in slices
Variable duration depending on system size, typically 6 to 18 months for a meaningful enterprise system. Each slice follows the same internal pattern: build, validate, parallel-run, cutover, observe. The legacy system remains available throughout. The new system absorbs traffic progressively.
Stage 4: Cutover as a structured event
Cutover is the highest-risk moment in the engagement. We treat it as a structured event with rehearsals, named go and no-go criteria, documented backout procedures, and a clearly defined incident response plan. Cutover happens during a planned window, with all stakeholders briefed in advance and on standby during the change.
Stage 5: Stabilization and legacy decommissioning
Two to four weeks of intensive monitoring after cutover. Performance regressions, edge cases, and integration issues that escaped the pre-cutover testing surface in this window. The legacy system stays available as fallback during stabilization. Decommissioning happens only after stabilization completes cleanly, with all rollback paths preserved until decommissioning is confirmed.
When Legacy Modernization Is the Wrong Move (Right Now)
Not every legacy system should be modernized this quarter. Here is when we tell clients to wait or pick a different path.
The system is stable, compliant, and infrequently changed. If the legacy system runs reliably, has unbroken audit trails, and rarely needs feature changes, the migration risk often outweighs the benefit. Retain is a legitimate strategy. Plan for eventual modernization, but don’t rush it ahead of higher-leverage work.
The organization isn’t ready to operate the new architecture. Modern cloud-native, microservices-based, or AI-integrated architectures require operational maturity that legacy operations teams may not have. Without that capability built first, the modernized system decays faster than the legacy one. Build the operating model before the architecture lands, not after.
Discovery isn’t yet funded. Discovery is the cheapest part of the project and the part most likely to be cut. If the organization isn’t ready to fund four to eight weeks of disciplined discovery before build, the project is being scoped to fail. Wait until discovery has executive backing.
The business case is technical preference, not measurable outcomes. “Move off the mainframe” is not an outcome. “Cut transaction processing time from 4 hours to 15 minutes” is. Programs scoped against technology drift. Programs scoped against business outcomes deliver, because architecture decisions get pressure-tested against value rather than aesthetics.
How Ariel Approaches Legacy Modernization
Across enterprise and mid-market clients, our legacy system modernization services are anchored on the risk-reduction approach described above. Discovery first, target architecture against discovery output, migration in slices with rollback at every stage, structured cutover, monitored stabilization. The disciplines apply regardless of which modernization pattern fits the system (rehost, replatform, refactor, rearchitect, rebuild).
The operating principles we apply across legacy system modernization services engagements are:
- Discovery as a funded line item, not an afterthought. Four to eight weeks before build commits. The cheapest investment in the project and the highest-leverage one.
- Knowledge capture before key engineers leave. Walk-throughs recorded, ADRs produced as the team learns the system, documentation as a sprint deliverable.
- Rollback paths preserved at every stage. No irreversible cutovers, no big-bang launches, no points where the only option is forward.
- Observability and audit designed in, not retrofitted. Distributed tracing, structured logging, compliance controls built into the new architecture from sprint one.
Across industries, we’ve applied this approach to modernization engagements in regulated and high-volume environments. In our financial services work, modernization typically involves consolidating legacy transaction systems with strict audit requirements and zero-tolerance cutover windows. In our real estate work, modernization often consolidates document routing, compliance workflows, and multi-party transaction tracking off aging systems. The pattern across industries is consistent: the risk-reduction discipline determines whether the migration produces ROI or produces overrun.
Planning a legacy modernization and want a delivery-grade scoping conversation, not a vendor pitch?
Our team has delivered legacy modernization engagements across enterprise and mid-market clients for 16 years. We’ll review your existing system, the risks that consistently surface in projects like yours, and the risk-reduction disciplines that prevent the most expensive failure modes from showing up nine months in.
Frequently Asked Questions
1. How long does a legacy system modernization typically take?
Discovery and target architecture together typically run 7 to 14 weeks. Migration duration depends on system size and chosen pattern. Focused infrastructure migrations (rehost or replatform) run 2 to 6 months. Phased refactoring or rearchitecting of complex monoliths runs 9 to 24 months. Multi-system portfolio modernizations typically run 2 to 5 years as a sequence of smaller engagements. The biggest variable isn’t engineering complexity; it’s the operational readiness and change management capacity in the receiving organization.
2. What does legacy application modernization services cost?
Legacy application modernization services cost ranges depend heavily on system complexity, integration surface, data volume, and chosen pattern. From our delivery experience, infrastructure-focused rehosting and replatforming engagements typically land in the lower six figures. Refactoring and rearchitecting engagements run higher, often into the mid to high six figures or low seven figures for complex enterprise systems. Greenfield rebuilds of major systems land in the higher ranges. These are illustrative ranges from our project work, not industry-wide benchmarks. Plan for an annual run cost on top of build for post-modernization operations.
3. How do you choose between rehost, replatform, refactor, and rearchitect?
By matching the pattern to the binding constraint. If infrastructure is end-of-life, replatform. If code is unmaintainable but architecture is sound, refactor. If architecture is the constraint on velocity or scale, rearchitect. If the system is fundamentally misaligned with current business needs, rebuild. Most modernization portfolios end up using multiple patterns across different applications. A portfolio that uses only one pattern is almost always being mismanaged.
4. What’s the most common reason legacy modernization projects fail?
Skipped discovery. The pattern is so consistent across failed projects that it’s the single best predictor of whether a modernization will land cleanly. A four-week discovery investment saves months of rework. Compressing discovery to start build faster is the most expensive optimization most modernization projects make. Closely behind: big-bang cutovers without rollback paths, and tribal knowledge that walked out the door before it was captured.
5. Can Ariel handle the full legacy modernization end-to-end?
Yes. As a legacy software modernization company, we cover discovery, risk assessment, target architecture design, migration sequencing, data migration, CI/CD modernization, observability tooling, structured cutover, stabilization, and post-modernization support. Get in touch if you want a delivery-grade conversation about your specific system.
The Decision Behind the Decision
The strongest legacy system modernization services engagements aren’t the ones with the most ambitious target architecture. They’re the ones where the risk-reduction discipline is applied continuously from sprint one. Discovery before build. Knowledge capture before engineers rotate off. Rollback paths preserved at every stage. Compliance designed in, not retrofitted. The disciplines are not new. The discipline of applying them consistently is what separates projects that land cleanly from projects that stall.
Fund discovery. Map the risks before scoping the build. Sequence the migration in reversible slices. Treat cutover as a structured event with rehearsals and named go and no-go criteria. Monitor stabilization before decommissioning legacy. The architecture follows from those decisions, not the other way around.
Ready to scope a legacy modernization built on risk reduction, not just target architecture?
Book a free consultation with Ariel’s modernization team. We’ll assess your existing system, map the risks that consistently surface in projects like yours, and design a sequenced delivery plan that respects what the work actually costs.